Autoregressive Video Diffusion
This section reviews several representative training paradigms (Forcing methods) in autoregressive video diffusion models, all aiming to solve a core problem: how to efficiently convert a bidirectional attention multi-step diffusion model into a causal few-step autoregressive model.
1. Diffusion Forcing [NeurIPS 2024]
Paper: Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
Core idea: During training, each frame is assigned an independent, random noise level. Known history frames and frames to be generated are placed in the same diffusion forward process but with different noise timesteps, enabling the model to generate frames autoregressively. This design elegantly combines the variable-length generation advantage of next-token prediction with the trajectory guidance advantage of full-sequence diffusion.
2. CausVid [CVPR 2025]
Paper: From Slow Bidirectional to Fast Autoregressive Video Diffusion Models
Proposes a two-stage method to distill a bidirectional multi-step diffusion model into a few-step autoregressive video diffusion model:
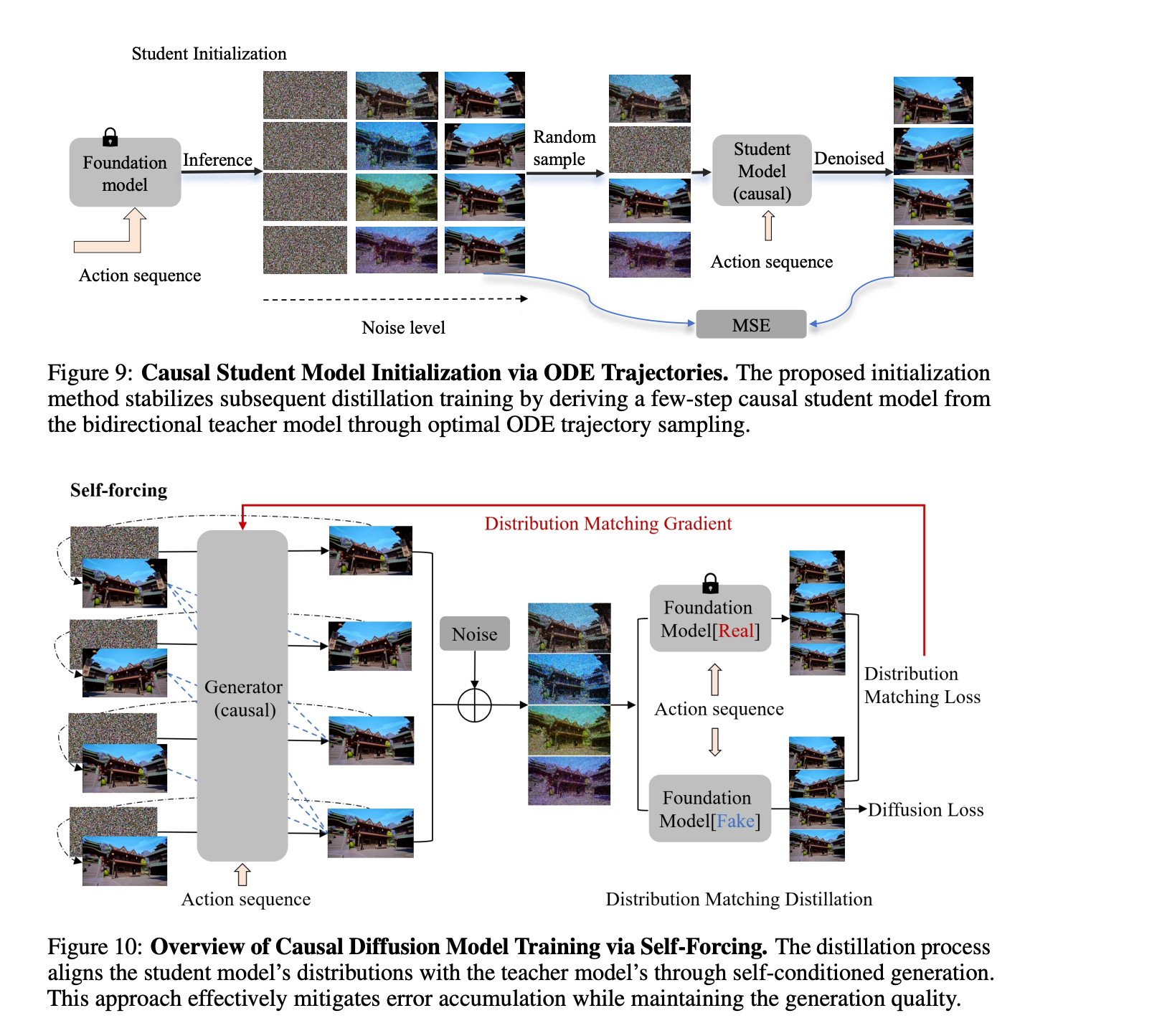
- ODE Regression Initialization: Use the teacher model to generate ODE pairs and train the student model's autoregressive capability with regression loss
- Asymmetric Distillation: Apply Diffusion Forcing strategy with DMD (Distribution Matching Distillation) loss to match the teacher model distribution, further aligning generation quality
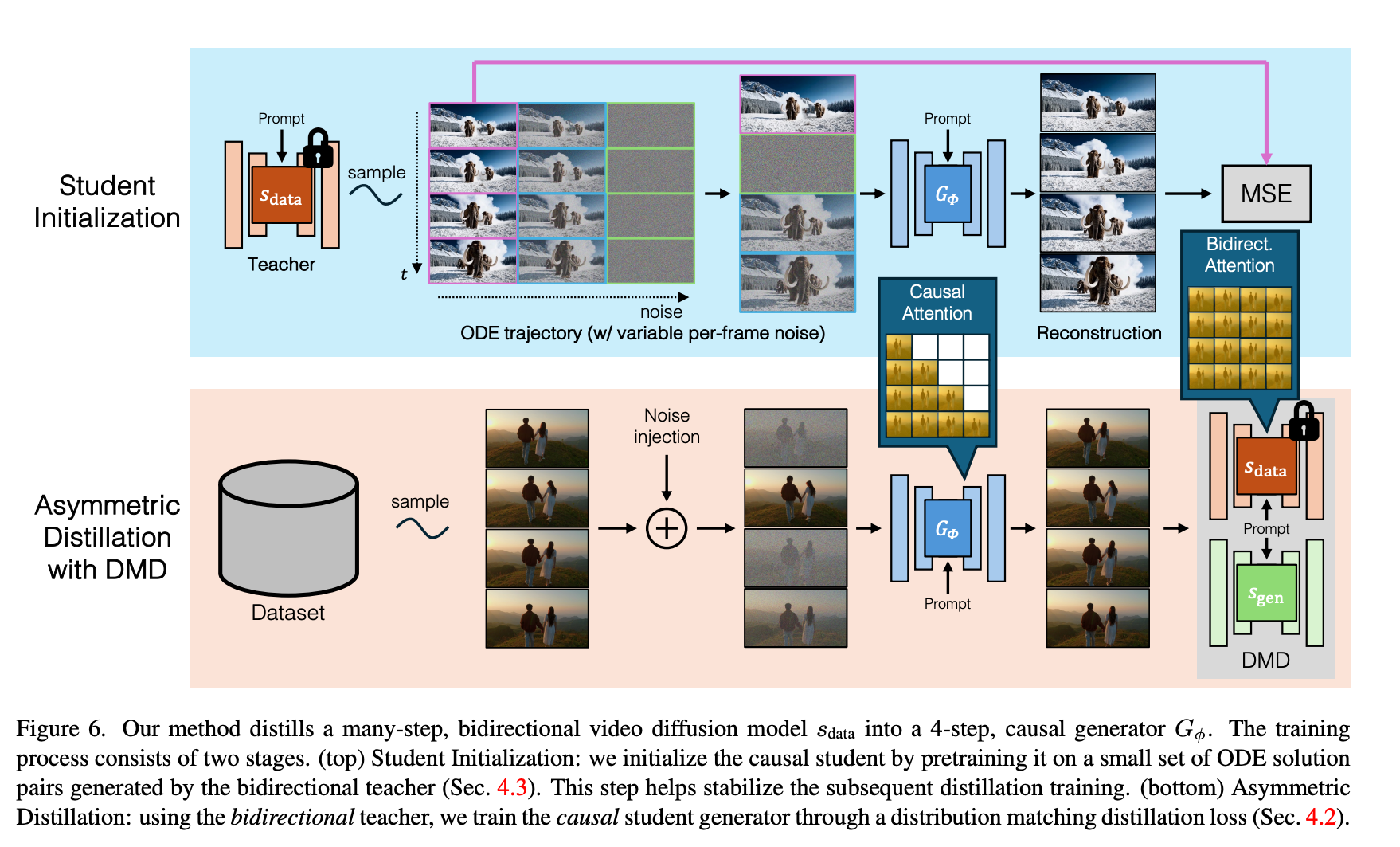 CausVid Training Framework Diagram
CausVid Training Framework Diagram
3. Self Forcing [NeurIPS 2025]
Paper: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Aims to solve the train-test distribution shift (Exposure Bias) caused by Teacher Forcing / Diffusion Forcing: during training, the model sees real frames, but during inference, it can only see its own generated frames.
Self Forcing simulates the actual inference process during training—performing autoregressive unrolling, predicting subsequent frames based on self-generated frames (KV Cache), while using a bidirectional teacher model to compute Distribution Matching Loss via DMD for supervision.
Comparison with CausVid: The first stage (ODE regression initialization) is identical; the difference lies in the second stage—Self Forcing does not use Diffusion Forcing but directly performs autoregressive unrolling during training.
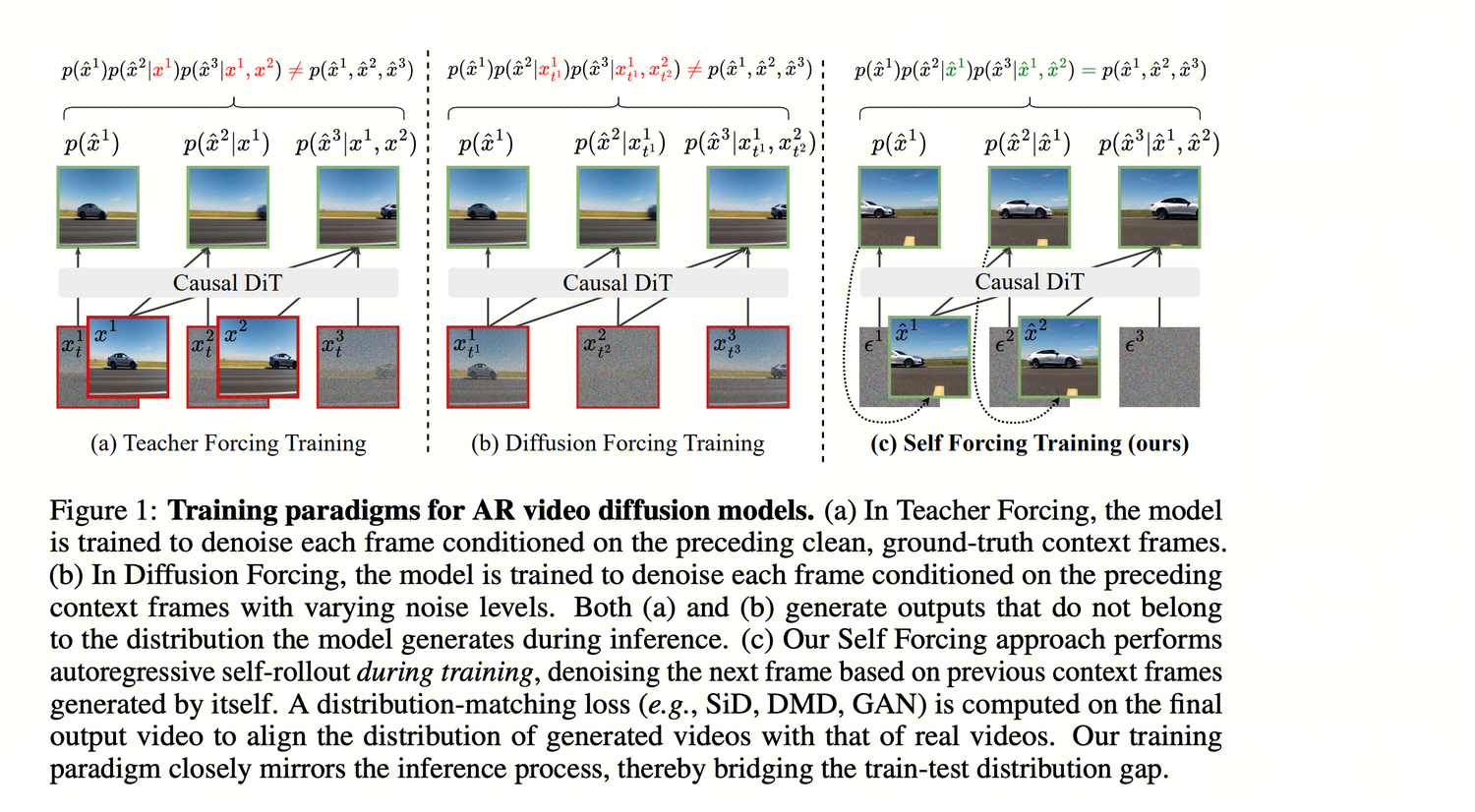 Training Method Comparison: Teacher Forcing vs. Diffusion Forcing vs. Self Forcing
Training Method Comparison: Teacher Forcing vs. Diffusion Forcing vs. Self Forcing
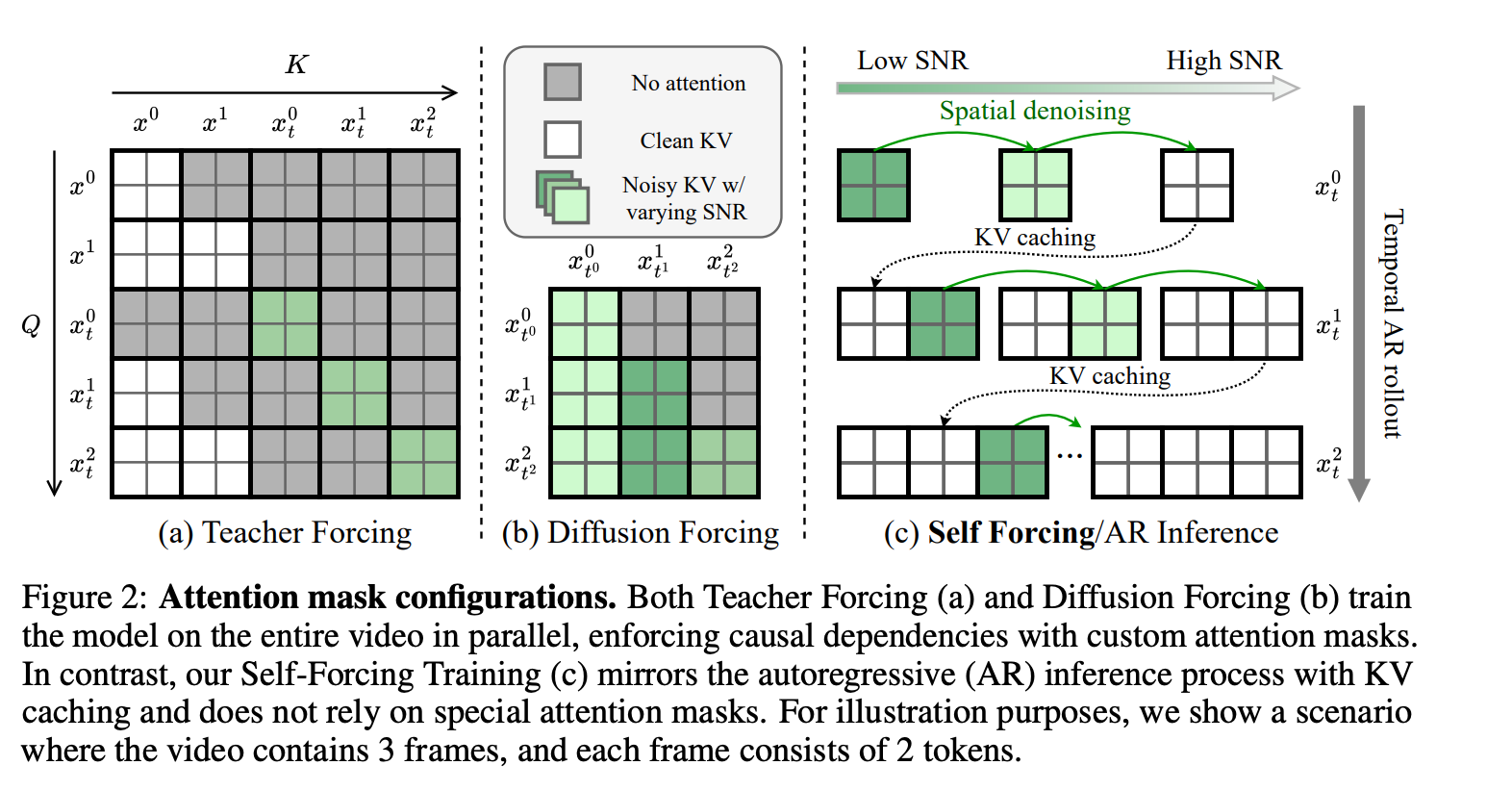 Attention Mechanism Comparison: Improved TF, DF, and SF (SF uses Full Attention, each chunk autoregressively unrolled)
Attention Mechanism Comparison: Improved TF, DF, and SF (SF uses Full Attention, each chunk autoregressively unrolled)
4. Causal Forcing
Paper: Causal Forcing: Autoregressive Diffusion Distillation Done Right
Theoretically points out the flaw of CausVid's direct distillation from bidirectional teacher to autoregressive student—it violates the frame-level injectivity condition of PF-ODE, causing the student model to degenerate into a conditional expectation solution.
Causal Forcing replicates Self Forcing's autoregressive unrolling in the DMD distillation stage, with the key improvement in the ODE initialization stage: first converting the bidirectional multi-step diffusion model to a multi-step autoregressive diffusion model (using Teacher Forcing), then performing ODE distillation to satisfy the injectivity condition.
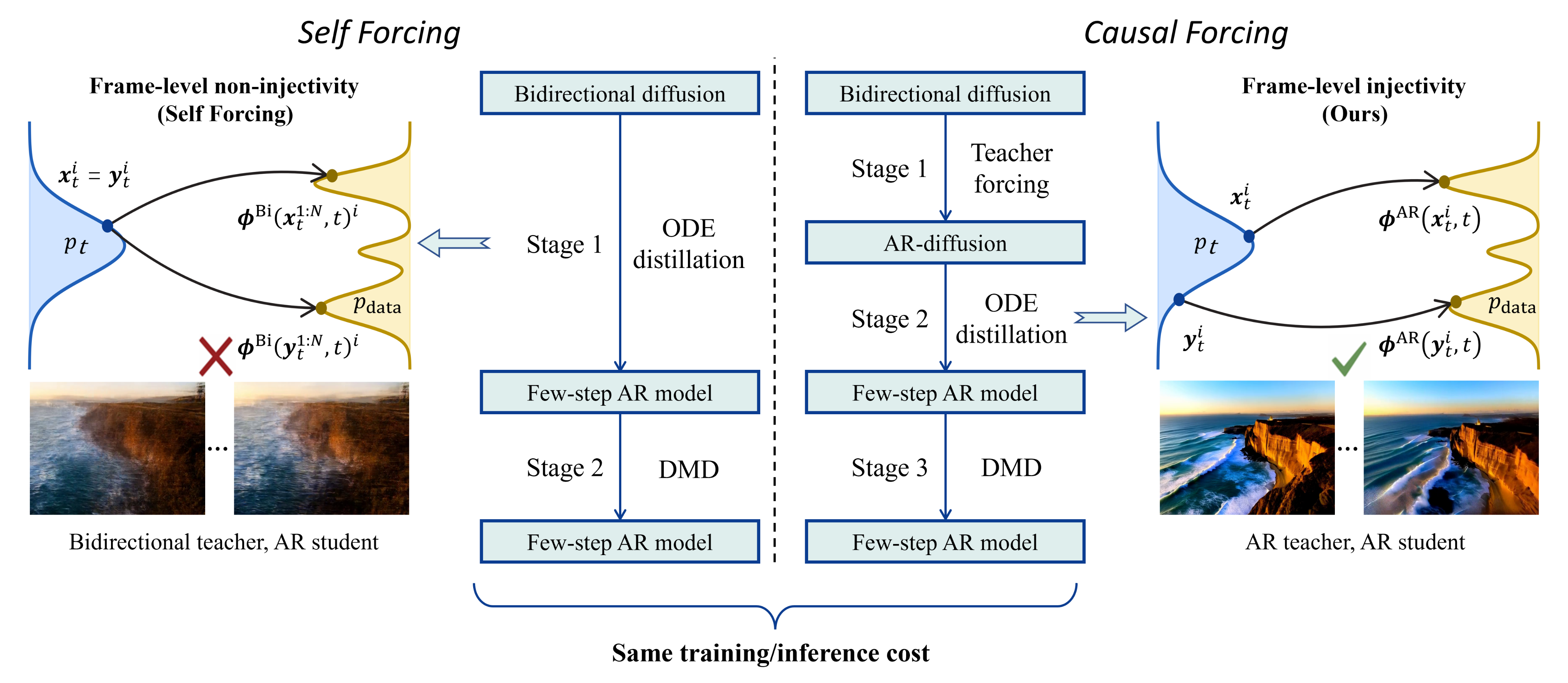 Causal Forcing Training Pipeline
Causal Forcing Training Pipeline
World Model (Interactive World Models)
The following are representative works on interactive world models, primarily focusing on action-conditioned video generation in game scenarios.
A useful tool: WMFactory — A unified frontend supporting deployment and experience of various interactive world models.
OASIS
Code: open-oasis
One of the earliest interactive world models with a relatively simple architecture, laying the foundation for subsequent works.
 OASIS Architecture
OASIS Architecture
GameFactory [ICCV 2025]
Paper: GameFactory: Creating New Games with Generative Interactive Videos | Code: GitHub
Dataset: GF-Minecraft (3 seeds × 3 weather × 6 time periods, totaling 2000 video clips, 2000 frames each, ~130 GB). HuggingFace Link
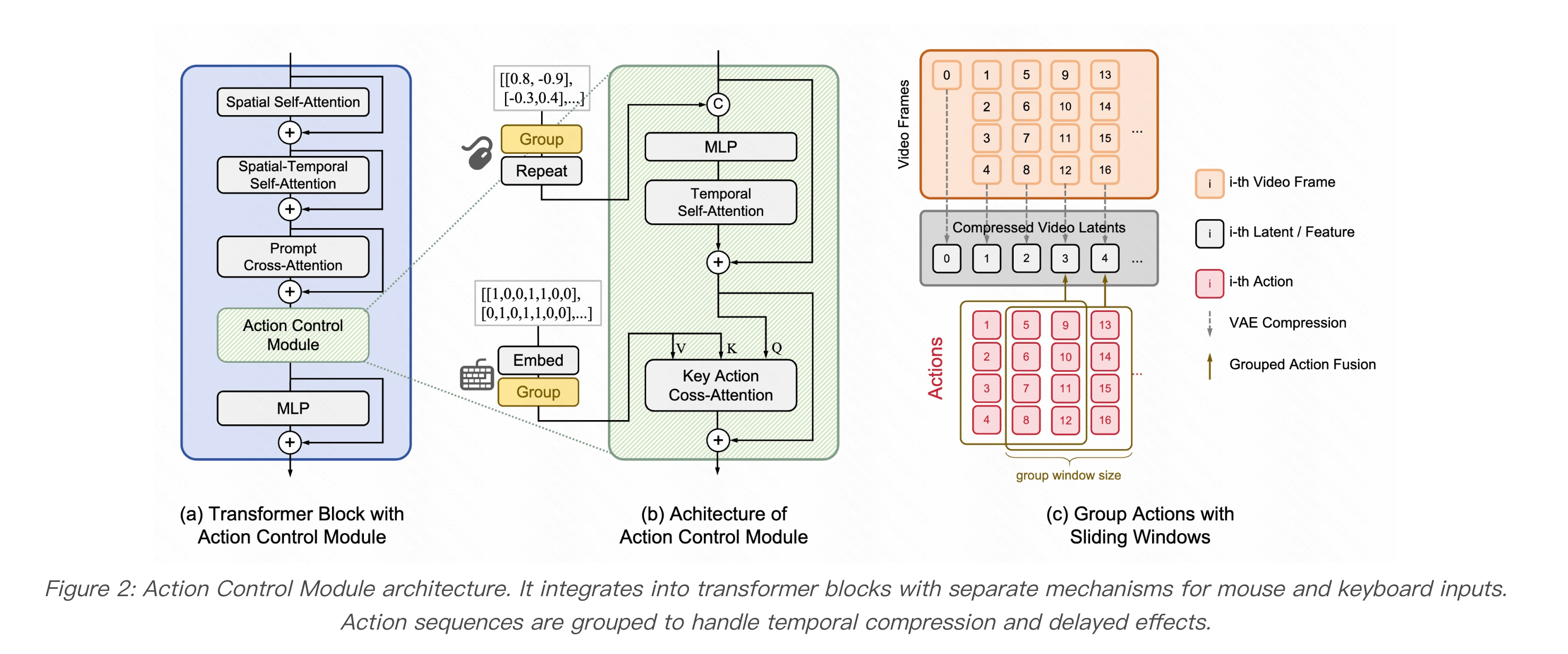 GameFactory Overall Architecture
GameFactory Overall Architecture
Action Control Module:
- Sliding Window Grouping: Video models typically compress along the temporal dimension (e.g., 16 frames compressed to 4 feature frames), causing misalignment between feature frames and high-frequency actions. Sliding windows bundle actions within corresponding time periods while simulating action delay effects (e.g., several frames of airborne time after pressing jump)
- Separate Mouse/Keyboard Processing:
- Mouse (continuous): Concatenated directly with video features
- Keyboard (discrete): Fused via Cross-Attention—keyboard signals as Key/Value, video features as Query
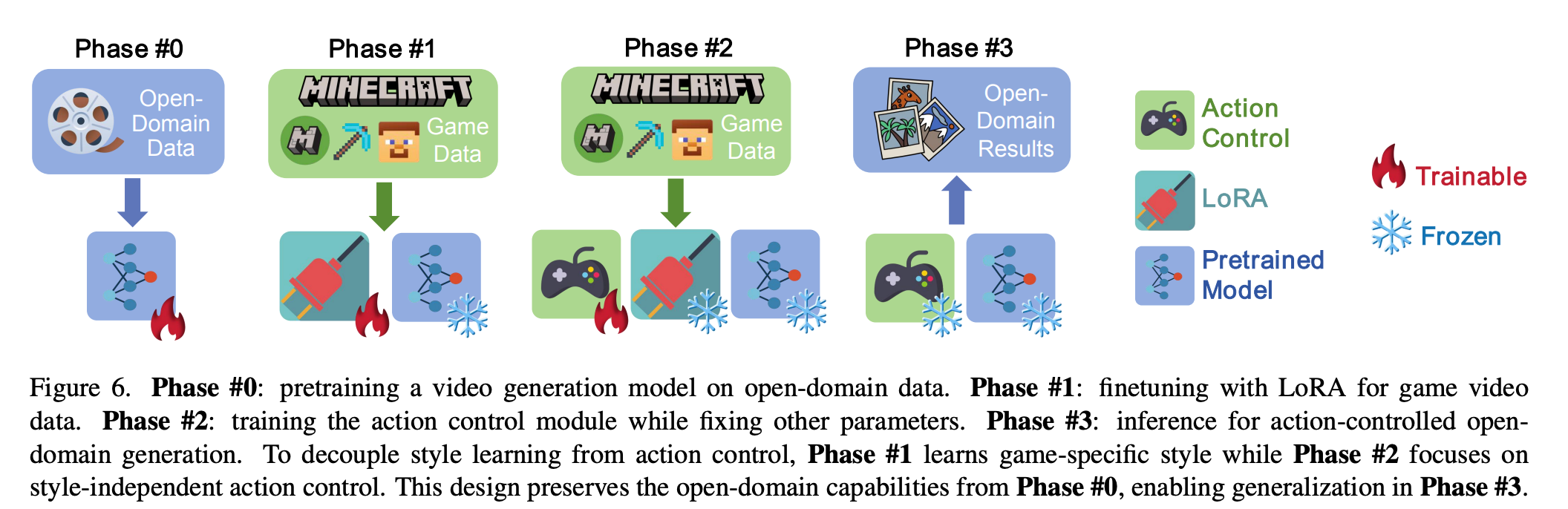 GameFactory Training Pipeline
GameFactory Training Pipeline
Phase 2 trains only the Action Control Module with a small amount of Minecraft data. Training/inference uses Diffusion Forcing.
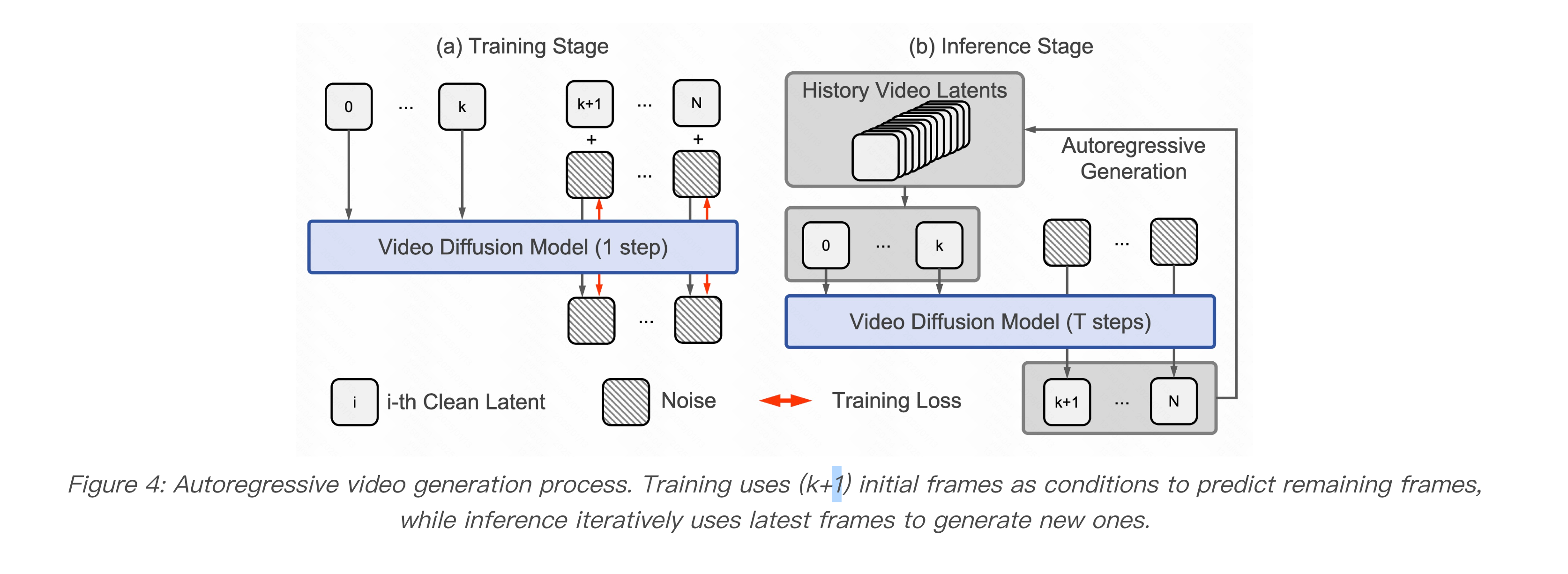 GameFactory Generation Process
GameFactory Generation Process
Matrix-Game 2.0
Paper: Matrix-Game 2.0: An Open-Source Real-Time and Streaming Interactive World Model
Based on Skyreels-V2 as the base model, fully replicating the Self Forcing training paradigm—first ODE initializing the student model, then completing distillation through DMD.
 Matrix-Game 2.0 Overall Architecture
Matrix-Game 2.0 Overall Architecture
Action Injection: Designs an independent Action Module. Continuous mouse movements are directly concatenated, while discrete keyboard actions are injected via Cross-Attention (same as Solaris and GameFactory).
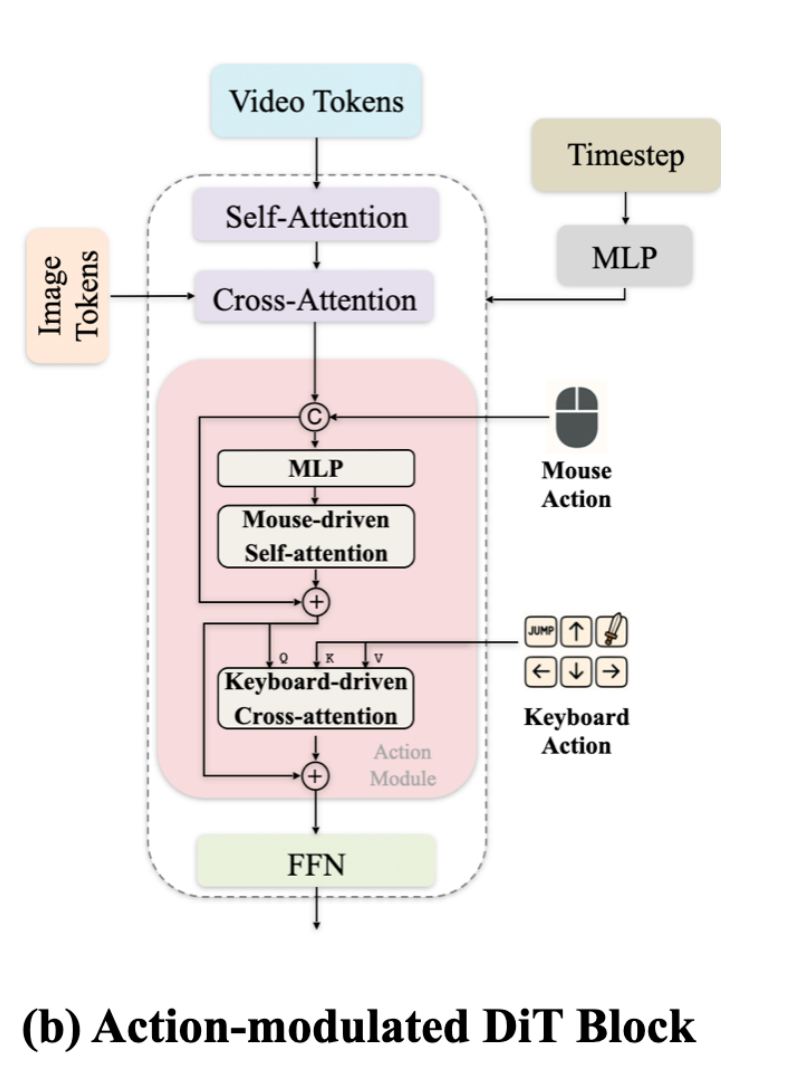 Matrix-Game 2.0 Action Injection
Matrix-Game 2.0 Action Injection
Solaris
Paper: Solaris: Building a Multiplayer Video World Model in Minecraft (by Saining Xie et al.)
Builds upon Matrix-Game 2.0 by introducing multiplayer support and improving the training pipeline, while keeping the same action injection scheme.
 Solaris Overall Architecture
Solaris Overall Architecture
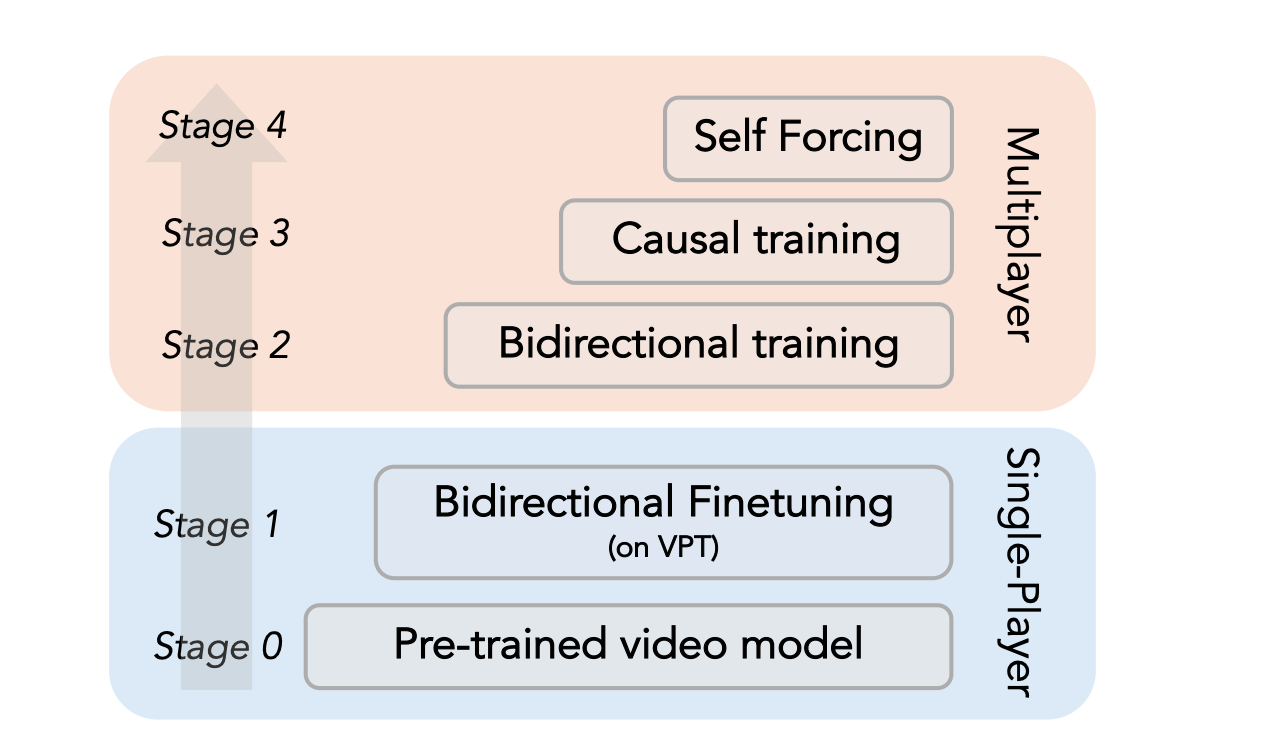
Four-Stage Training Pipeline:
Stage 1: Fine-tune the bidirectional model on VPT (OpenAI's Minecraft dataset, 120K steps, 33 frames)
Stage 2: Improve DiT architecture to support multiplayer
- Each player's tokens use independent 3D RoPE
- Learned Player ID Embeddings are injected at the beginning of the Multiplayer Shared Self-Attention Layer
- Full-sequence bidirectional training on the dataset (120K steps)—this model serves as the teacher in Self Forcing
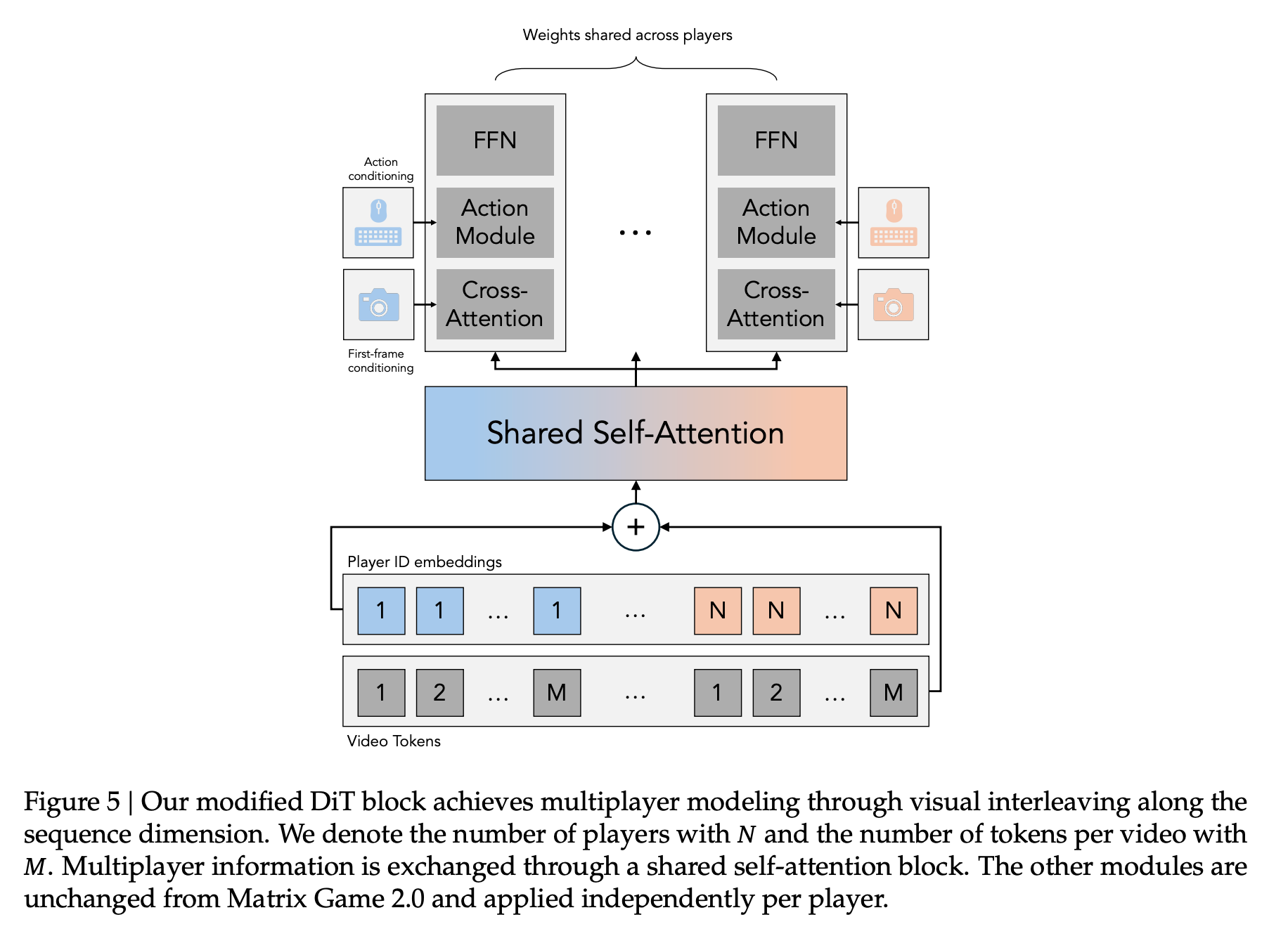 Solaris Multiplayer Attention Mechanism
Solaris Multiplayer Attention Mechanism
Stage 3: Causal Training
- Initialize causal model from the 60K steps checkpoint of bidirectional training
- Use a 6 latent frames sliding window attention mask (also the maximum window for KV cache during inference)
- Train with Diffusion Forcing, producing the model as Self Forcing's Generator (student model)
- Key finding: No complex ODE regression initialization needed—directly using the Diffusion Forcing output as Self Forcing's Generator suffices (consistent with LingbotWorld's conclusion)
Stage 4: Self Forcing
- Extend the Teacher's context length so that the Student benefits from a stronger Teacher
- Propose Checkpointed Self Forcing to solve the out-of-memory issue with sliding window settings: first generate the initial video without gradients and cache intermediate noised frames, then recompute the final video in an additional step with backpropagation enabled, decoupling autoregressive rollout from backpropagation
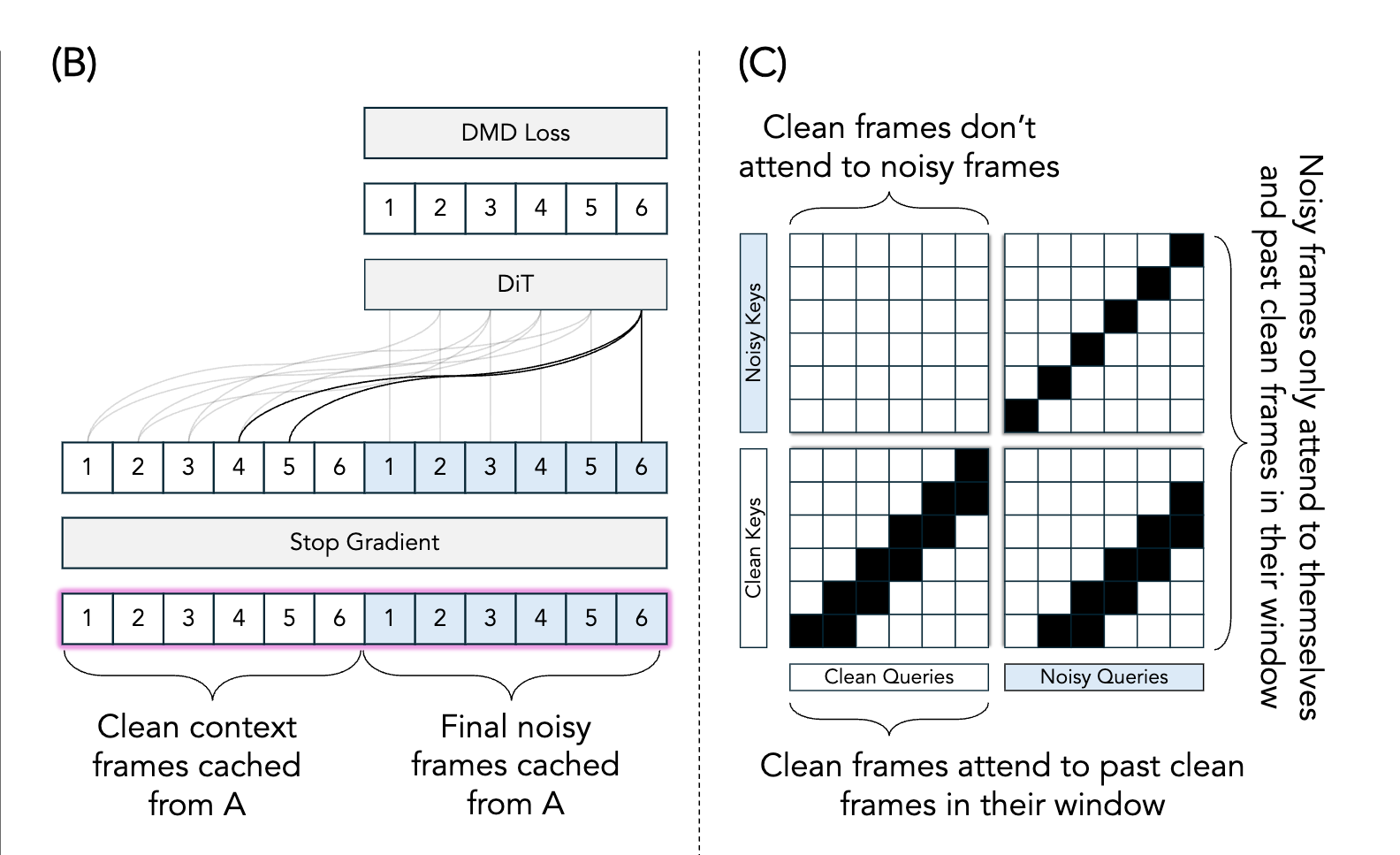 Solaris Self Forcing Pipeline
Solaris Self Forcing Pipeline
Attention Mechanism Interpretation: After concatenating 6 Clean Frames and 6 Noisy Frames:
- Clean Queries: Only attend to themselves and preceding clean frames within the window, not noisy frames
- Noisy Frames: Only attend to their own noised version and preceding clean frames within the window
- Through a single forward pass, this reproduces the effect of frame-by-frame autoregressive unrolling, while gradients can flow completely through the entire attention QKV
HYWorldPlay
Technical Report: HYWorld 1.5 Tech Report
Based on Wan-5B / HY-8B, trained in four stages:
 HYWorldPlay Four-Stage Training Pipeline
HYWorldPlay Four-Stage Training Pipeline
- Use Diffusion Forcing to train a Chunk-wise AR Diffusion Model (similar to Solaris)
- Action Injection:
- Discrete keyboard and mouse: Use zero-initialized MLP to project Action Embeddings, injected into timestep embedding (AdaLN modulator)
- Continuous camera pose: Injected into Self-Attention Blocks via PRoPE
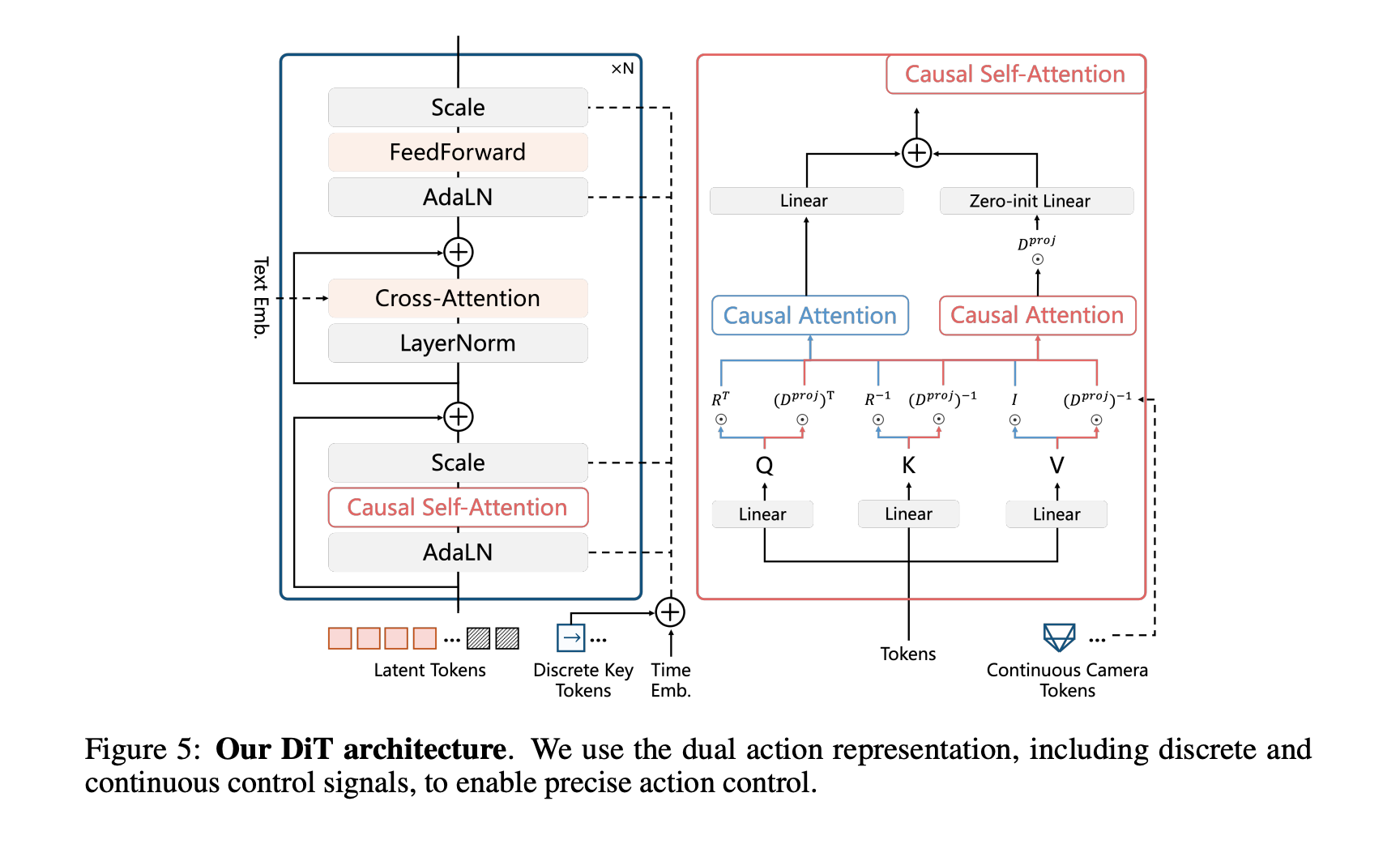 HYWorldPlay Action Injection Methods
3. Redesigned Context Memory:
HYWorldPlay Action Injection Methods
3. Redesigned Context Memory:
- Short-term temporal clues: Retain the most recent L chunks to maintain short-term action smoothness
- Long-range spatial references: Spatial Memory sampled from non-adjacent historical frames, guided by geometric relevance scoring (combining FOV overlap and camera distance)
- As shown, compared to (b) where absolute position encoding causes the distance between historical frames and current frames to keep growing, (c) reassigns relative positions, "compressing" all memory close to the current position in encoding, thereby avoiding RoPE long-distance degradation and maintaining long-term consistency.
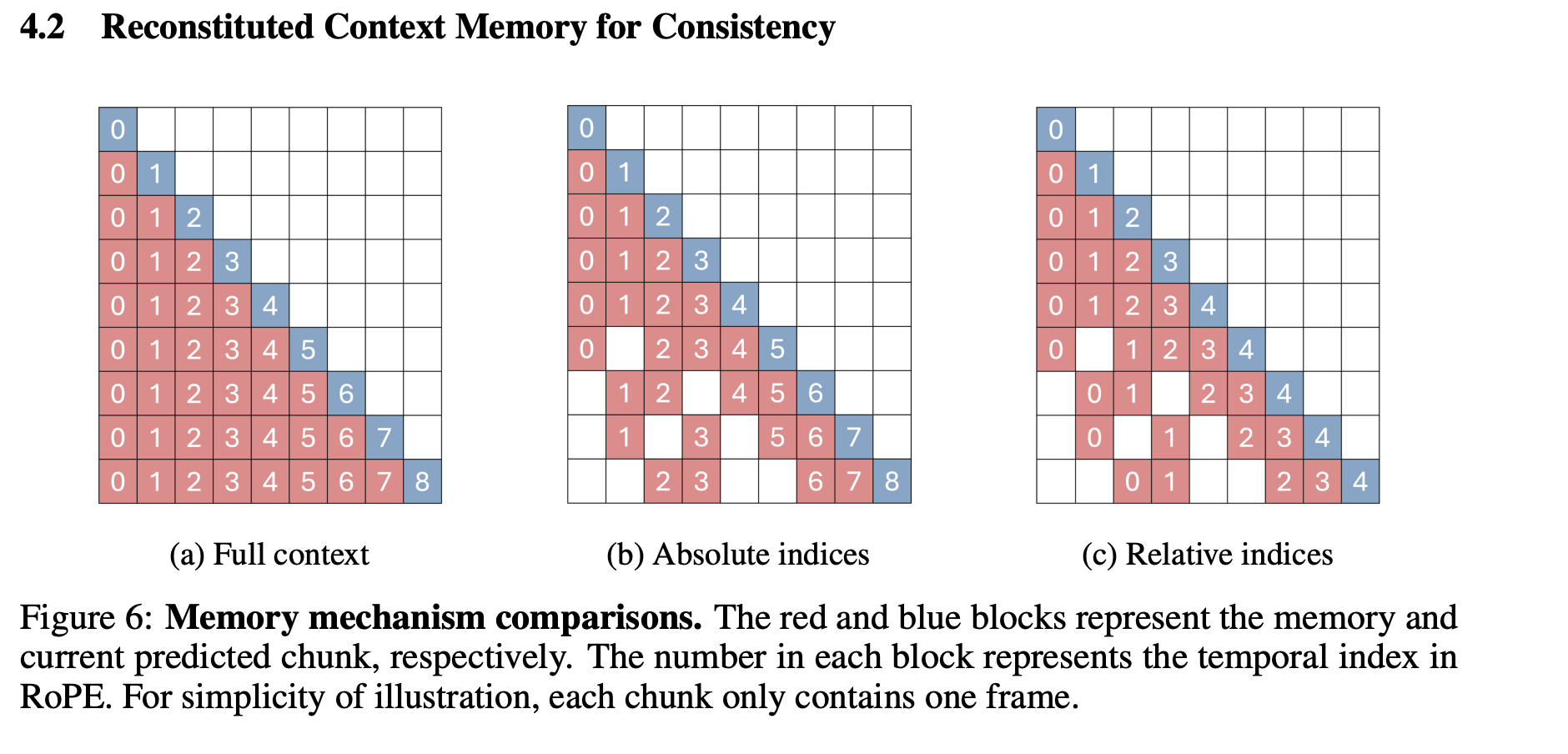 HYWorldPlay Context Memory
4. Post-training:
HYWorldPlay Context Memory
4. Post-training:
- Stage I: RL training using WorldCompass (open-sourced)
- Stage II: Proposes Context Forcing distillation method (not open-sourced, similar to Self Forcing)—passes the Memory used by the student's Self-Rollout over 4 chunks to the teacher, enabling the teacher to perform Distribution Matching under the same memory conditions
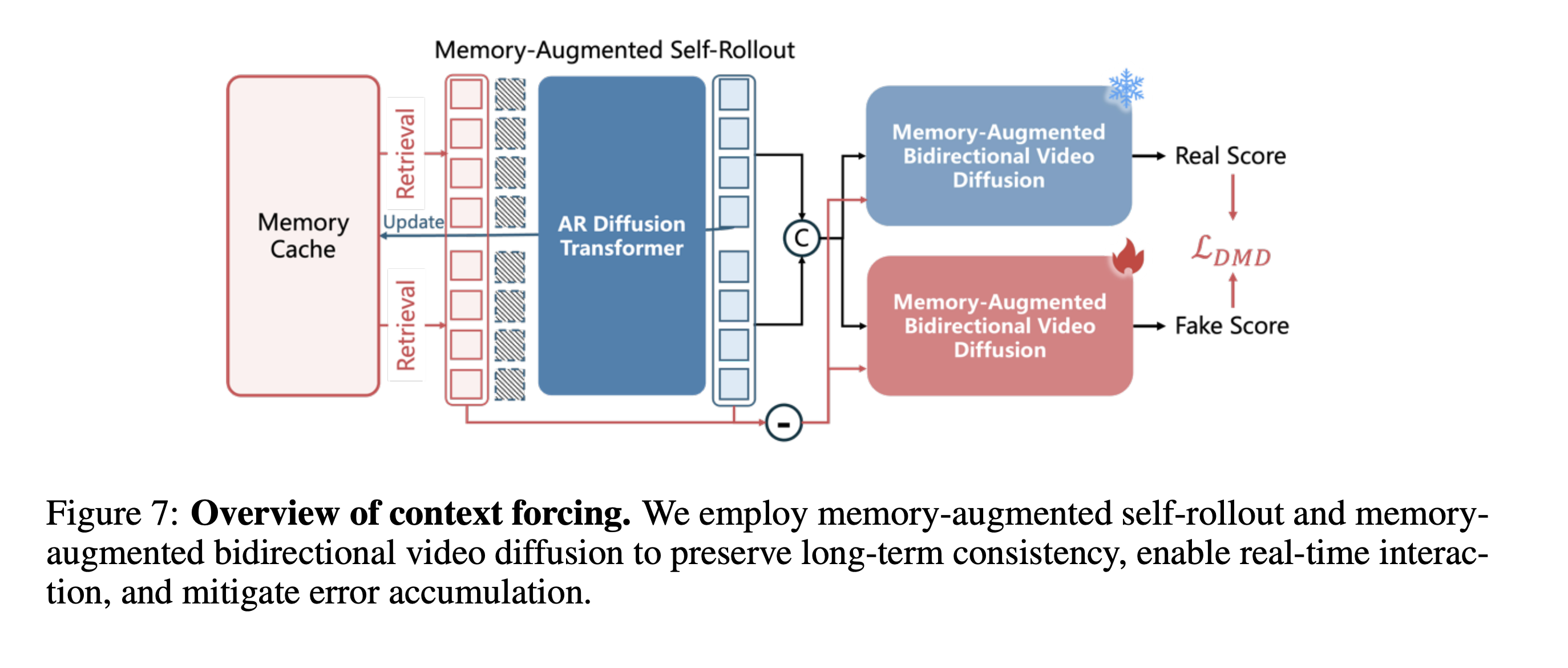 HYWorldPlay Post-training Distillation
HYWorldPlay Post-training Distillation
LingbotWorld
Paper: LingbotWorld
Based on Wan 2.1 14B I2V Model, three-stage training:
- General video prior learning
- Inject Actions, train for long-term consistency (bidirectional stage)
- Causal Attention + Few-Step distillation
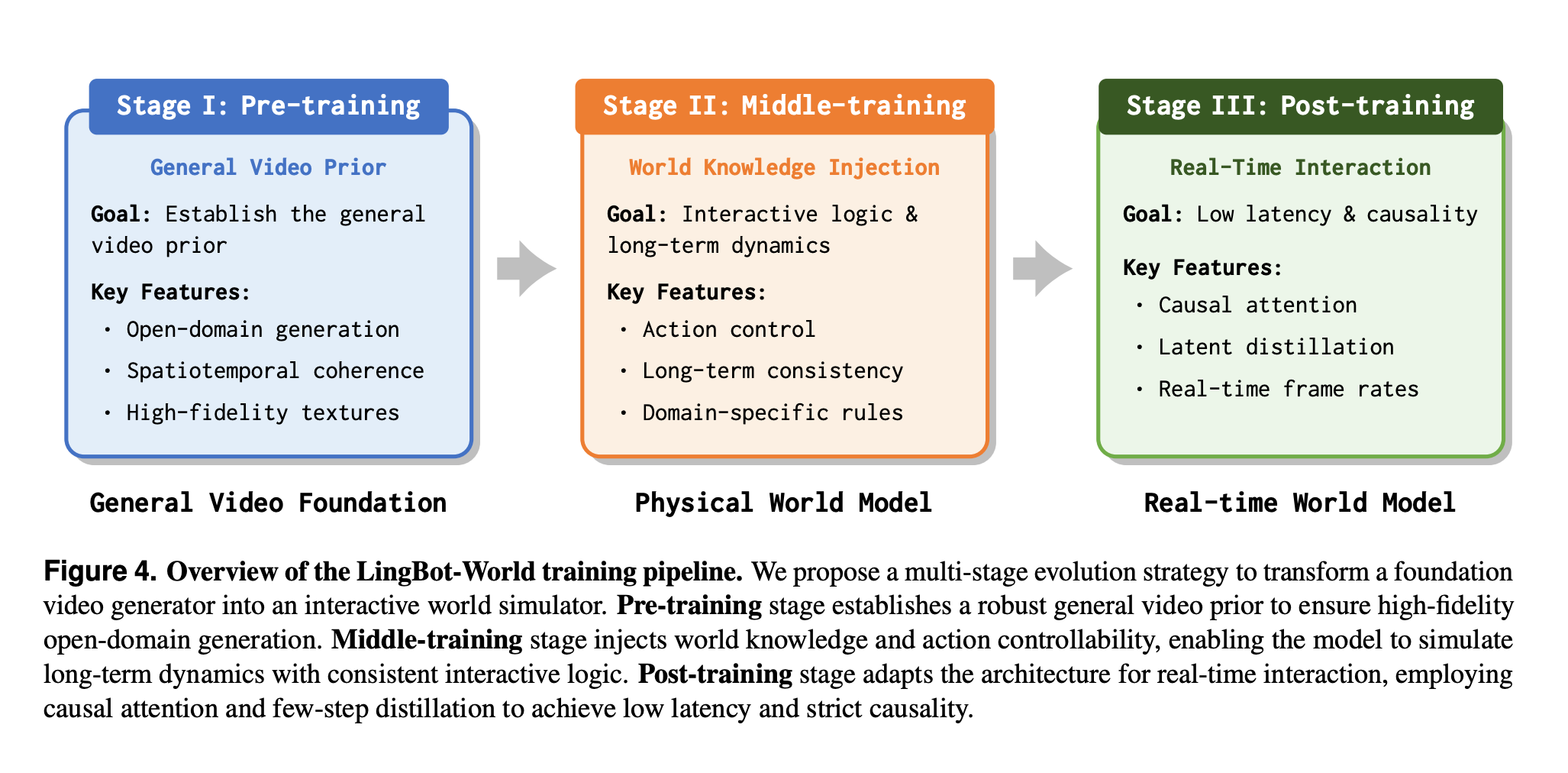 LingbotWorld Training Pipeline
LingbotWorld Training Pipeline
Action Injection: Unifies continuous and discrete signals—continuous signals use Plucker Embeddings, discrete signals use Multi-hop Vectors, both concatenated along the channel dimension and injected into the AdaLN modulator (similar to HYWorldPlay's discrete injection). During training, only the newly added Action Embeddings Projection layers and AdaLN parameters are fine-tuned, while the backbone is frozen.
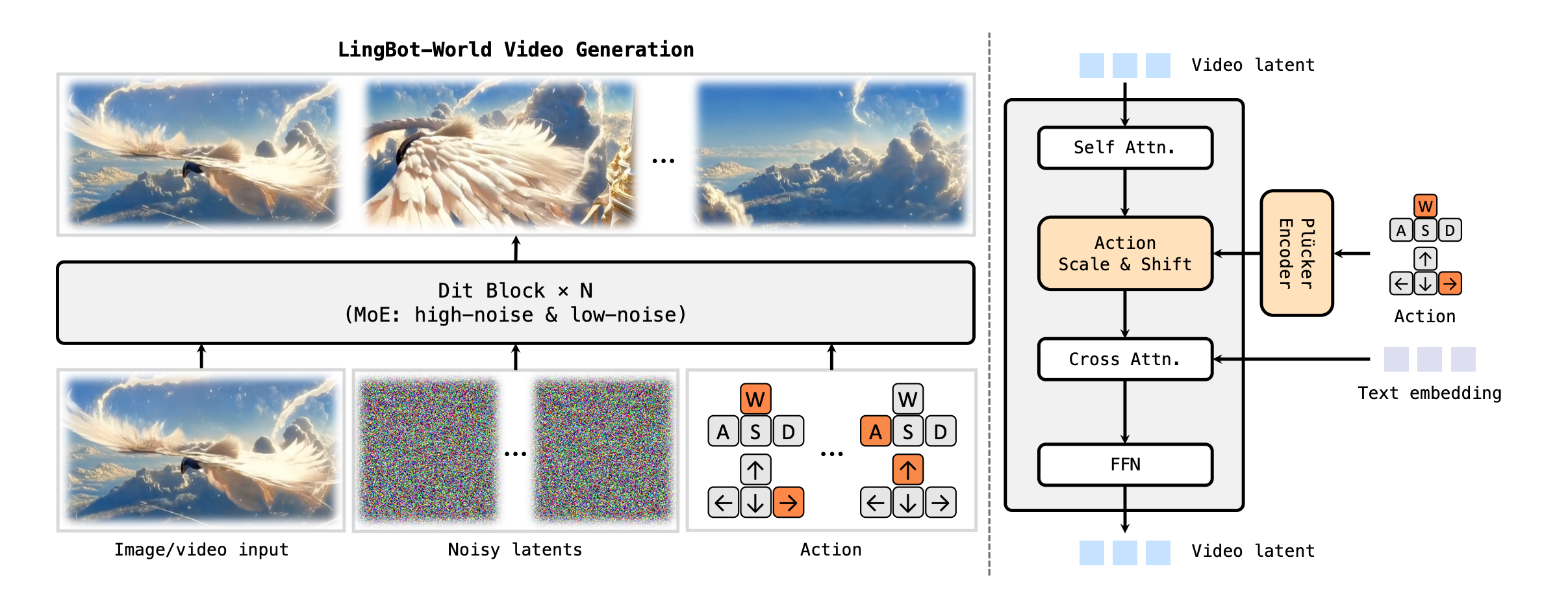 LingbotWorld Action Injection
LingbotWorld Action Injection
Training paradigm: First use Diffusion Forcing to convert the bidirectional model to an AR model, then distill with Self Forcing into a few-step model (directly using the Diffusion Forcing output as Teacher, without ODE initialization—consistent with Solaris's conclusion).
Matrix-Game 3.0
Code: Matrix-Game 3.0
Based on Wan 2.2 5B, abandons the Self Forcing + Causal Attention Mask paradigm:
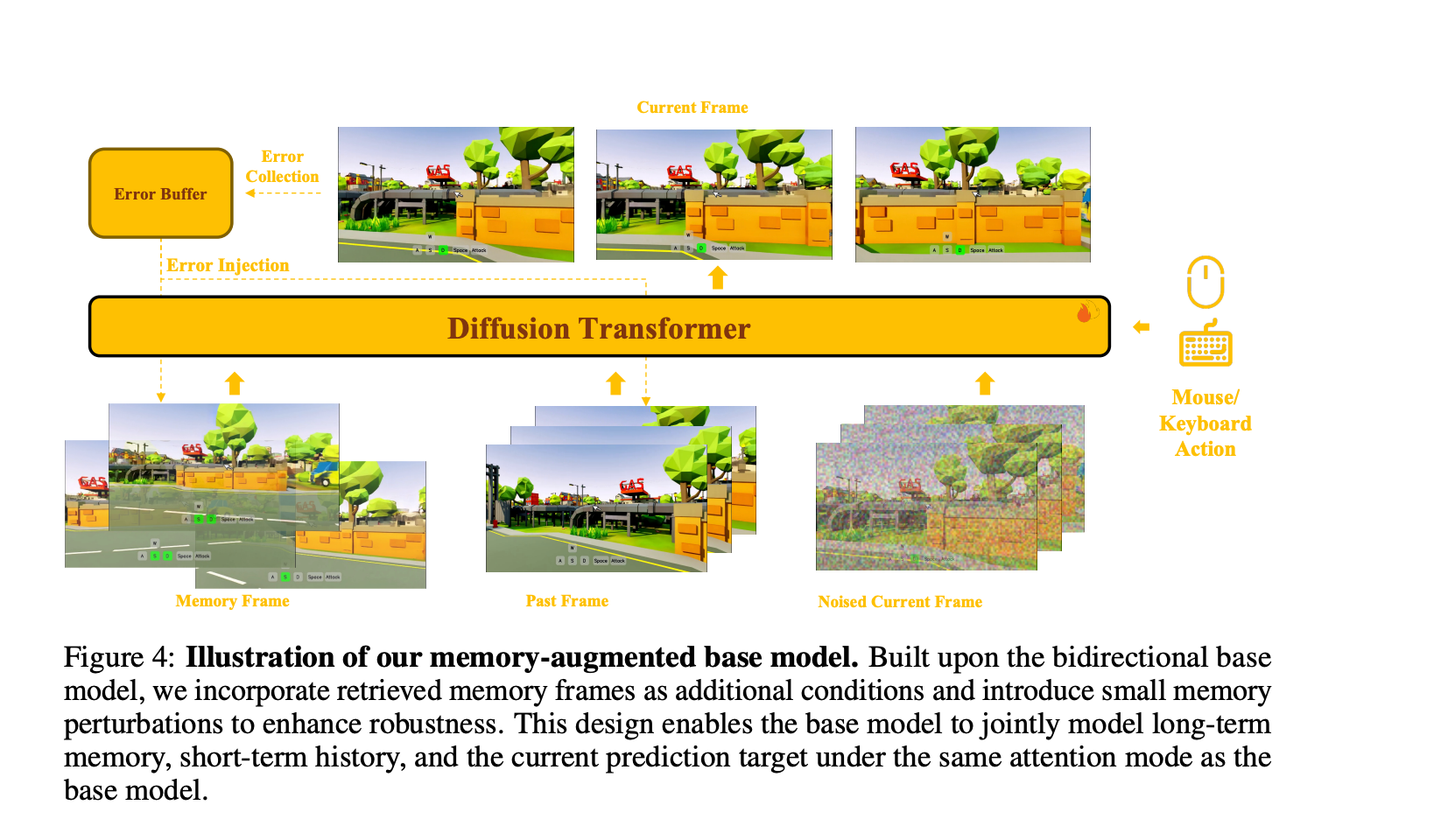 Matrix-Game 3.0 Architecture
Matrix-Game 3.0 Architecture
- Generates only one segment (56 frames) at a time; within a segment, full attention is used without attending to previous frames, conditioning only through overlap + memory
- Of the 56 frames, 16 are overlap, advancing 40 frames each time
- From the 40 frames, 5 keyframes are selected, and 5 similar Memory frames are retrieved via FOV overlap / camera pose, obtaining the corresponding 5 latent frames
- Finally, the 5 memory latent frames are merged with 14 segment-internal latent frames for bidirectional full attention diffusion
 Matrix-Game 3.0 Memory + Overlap Mechanism
Matrix-Game 3.0 Memory + Overlap Mechanism
Additionally, a Training-Inference Aligned few-step distillation method is proposed.
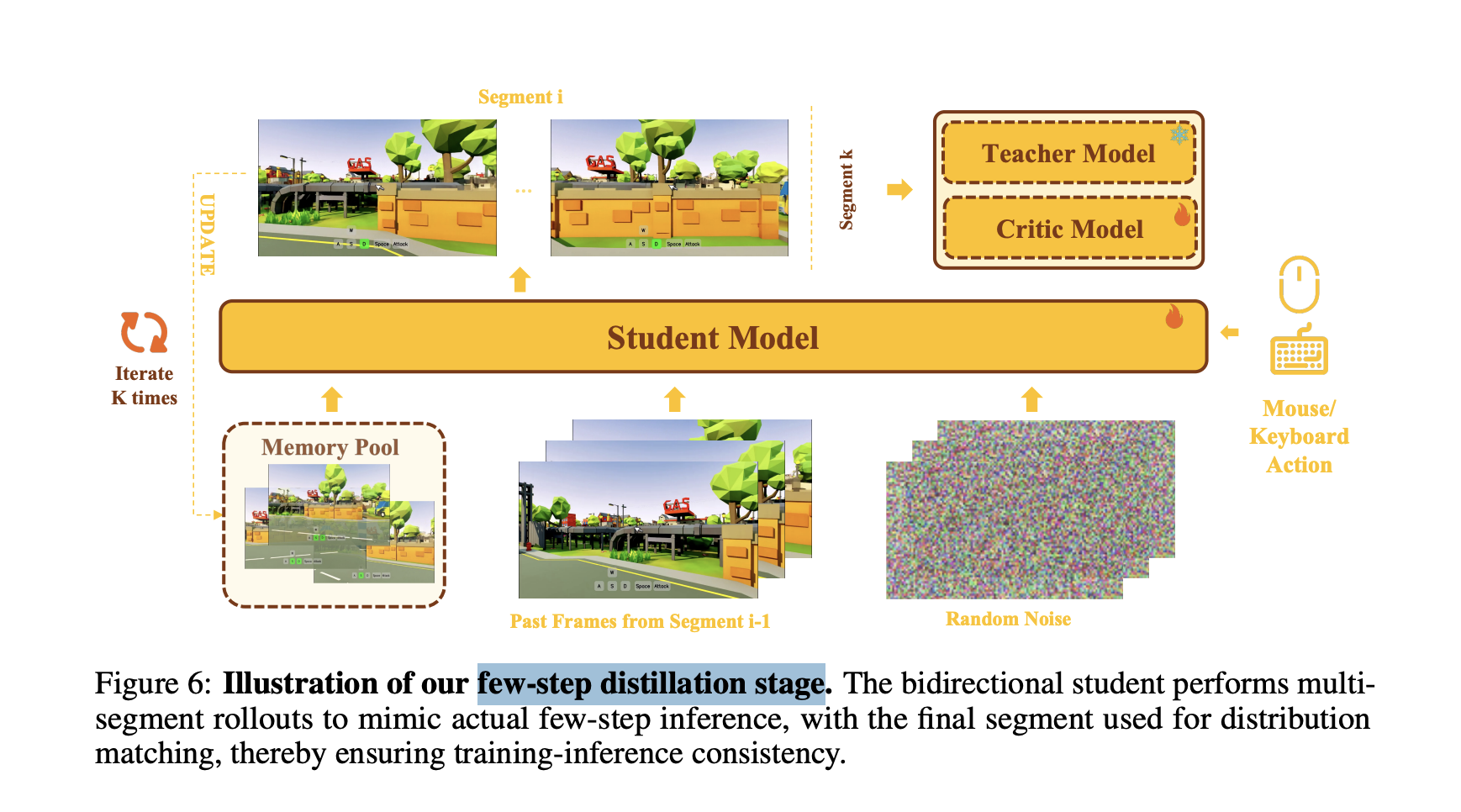 Matrix-Game 3.0 Few-step Distillation Stage
Matrix-Game 3.0 Few-step Distillation Stage
- Existing distillation methods use a Causal Student model with chunk-wise inference, naturally supporting self-rollout within the teacher window
- In contrast, the bidirectional student model no longer performs chunk-wise inference but instead covers the entire window like the teacher. Thus, relying solely on a single window cannot provide the biased-but-clean historical frames needed for self-rollout (similar to Self Forcing); simply using ground-truth causes mismatch
- A multi-segment self-generated inference scheme is introduced, rolling out across multiple segments to simulate the actual few-step inference process
My understanding is that the segment here can essentially be seen as an extended version of a chunk. In fact, each chunk also uses bidirectional full-attention internally, except traditional chunks typically only have 3 latent frames, whereas segments here have 14 latent frames. Additionally, the way inter-chunk relationships are handled differs: previous Causal Attention attended to preceding chunks through self-attention (via KV Cache), while here, attention is no longer used—historical latents are saved and directly concatenated after FOV/pose matching.
Upon careful consideration, the two approaches are fundamentally similar. However, only 5 historical latents are taken here, which may not be optimal for Memory, and there should still be considerable room for improvement in ensuring long-range consistency regardless of the approach.
Summary
Action Injection Methods
| Approach | Representative Works |
|---|---|
| Action Module: Continuous signals Concat + Discrete signals Cross-Attention | Matrix-Game 2.0/3.0, Solaris, GameFactory |
| Action Embeddings injected into AdaLN modulator | HYWorldPlay, LingbotWorld |
Training Paradigms
Core objective: Convert bidirectional model to AR model + Distill multi-step model to few-step model.
| Training Method | Representative Works |
|---|---|
| Diffusion Forcing | GameFactory |
| Self Forcing | Matrix-Game 2.0 |
| Diffusion Forcing → Self Forcing (Stage 2) | Solaris, LingbotWorld |
| Non-Causal Attention + Forcing Paradigm (Segment-based) | Matrix-Game 3.0 |