Autoregressive Video Diffusion
本节梳理自回归视频扩散模型中几种代表性的训练范式(Forcing 方法),它们致力于解决同一个核心问题:如何将双向注意力的多步扩散模型高效转化为因果的少步自回归模型。
1. Diffusion Forcing [NeurIPS 2024]
论文: Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
核心思路:训练时为每一帧分配独立、随机的噪声水平,将已知的历史帧与待生成的未来帧放在同一个扩散前向过程中,但赋予它们不同的噪声时间步 (timestep),从而使模型具备逐帧自回归生成的能力。这一设计巧妙地融合了 next-token prediction 的可变长度生成优势与 full-sequence diffusion 的轨迹引导优势。
2. CausVid [CVPR 2025]
论文: From Slow Bidirectional to Fast Autoregressive Video Diffusion Models
提出将双向多步扩散模型蒸馏为少步自回归视频扩散模型的两阶段方法:
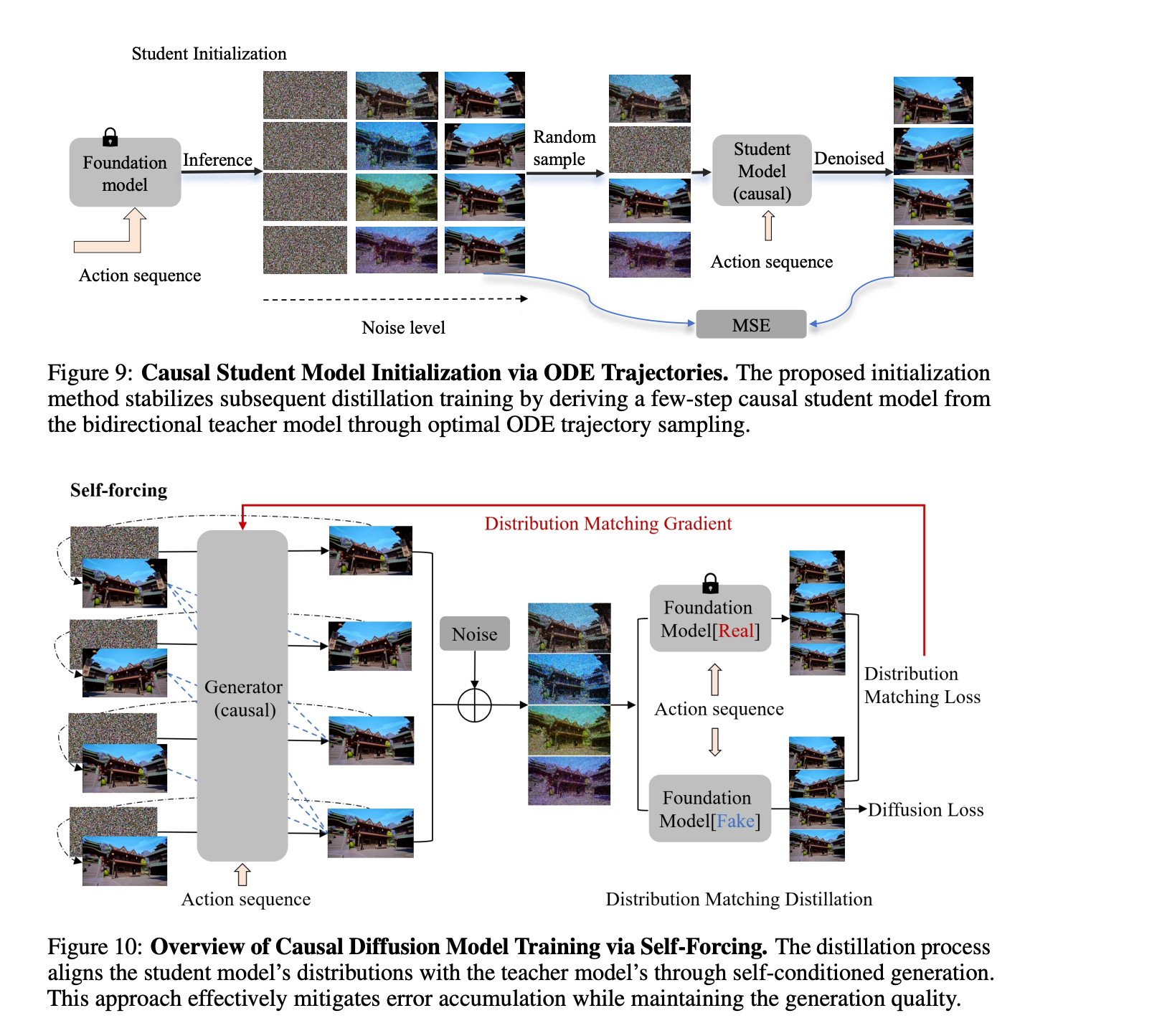
- ODE 回归初始化:用教师模型生成 ODE pair,以回归损失训练学生模型的自回归能力
- 不对称蒸馏:采用 Diffusion Forcing 策略,通过 DMD (Distribution Matching Distillation) 损失匹配教师模型分布,进一步对齐生成质量
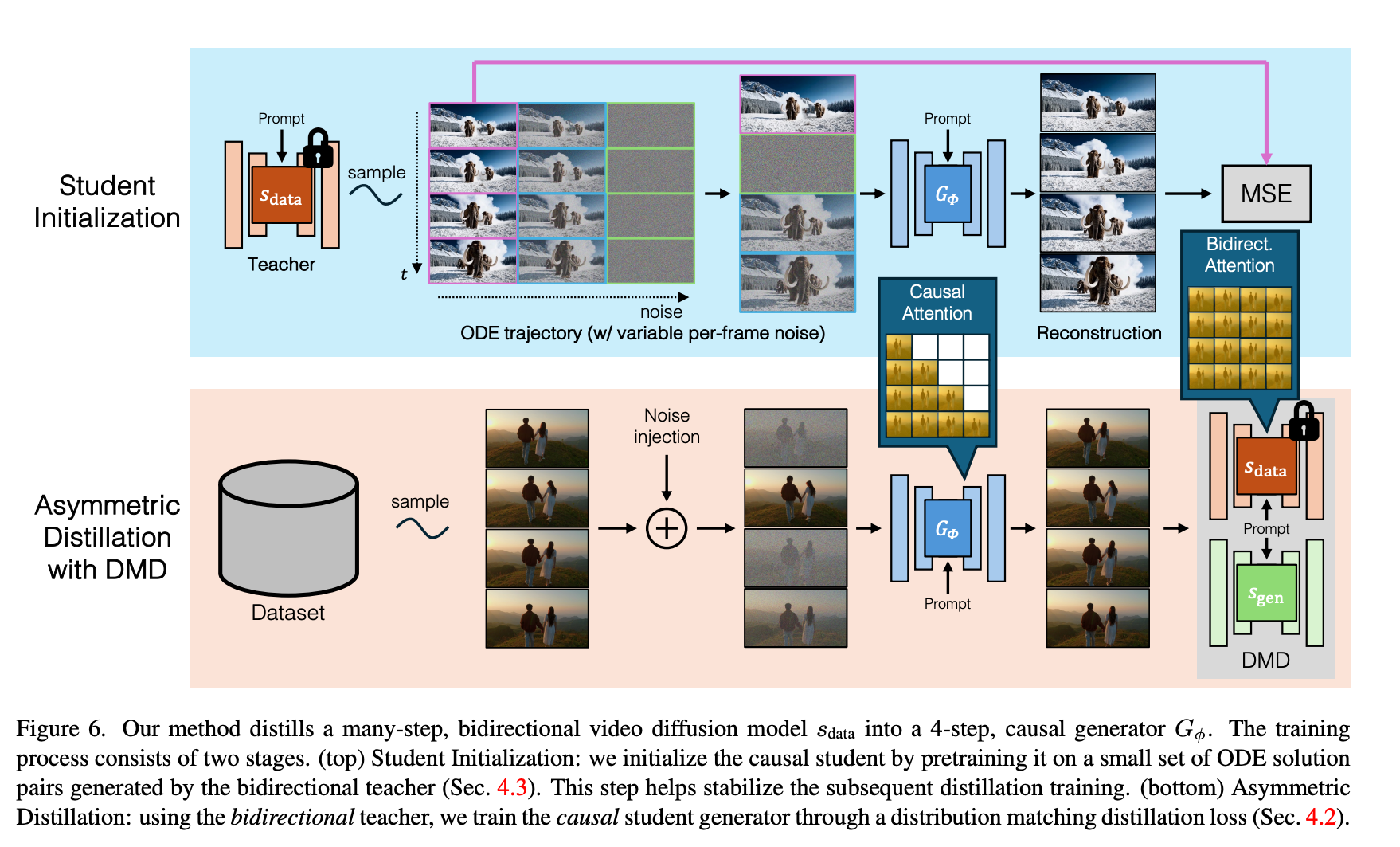 CausVid 训练框架示意图
CausVid 训练框架示意图
3. Self Forcing [NIPS 2025]
论文: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
旨在解决 Teacher Forcing / Diffusion Forcing 所导致的训练-推理分布偏移(曝光偏差,Exposure Bias):训练时模型看到的是真实帧,而推理时只能看到自己生成的帧。
Self Forcing 的做法是在训练阶段就直接模拟真实推理过程——进行自回归展开,基于自身生成的帧(KV Cache)预测后续帧,同时引入双向教师模型通过 DMD 计算 Distribution Matching Loss 进行监督。
与 CausVid 的对比:第一阶段(ODE 回归初始化)完全相同,区别在第二阶段——Self Forcing 不使用 Diffusion Forcing,而是直接在训练中自回归展开。
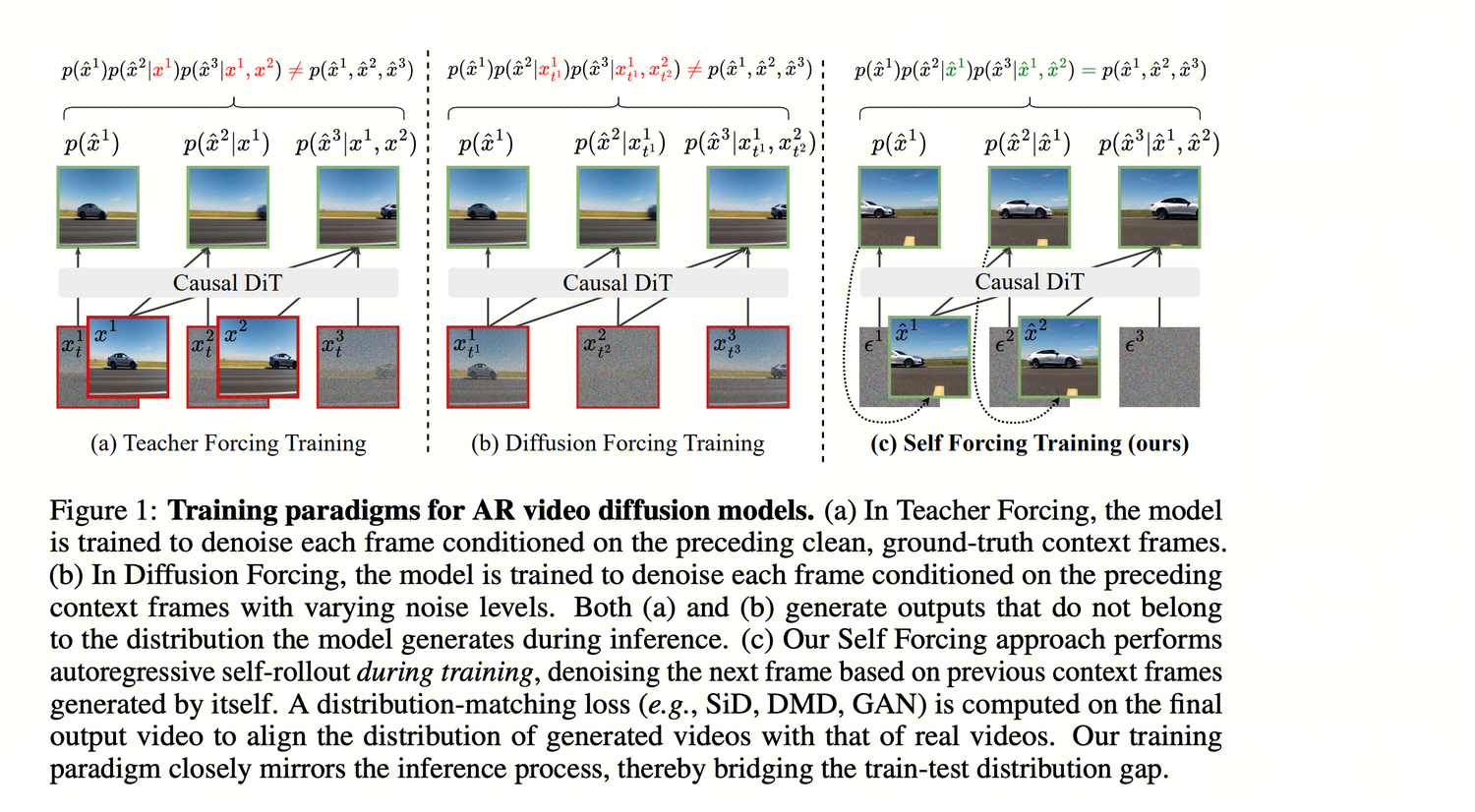 训练方法对比:Teacher Forcing vs. Diffusion Forcing vs. Self Forcing
训练方法对比:Teacher Forcing vs. Diffusion Forcing vs. Self Forcing
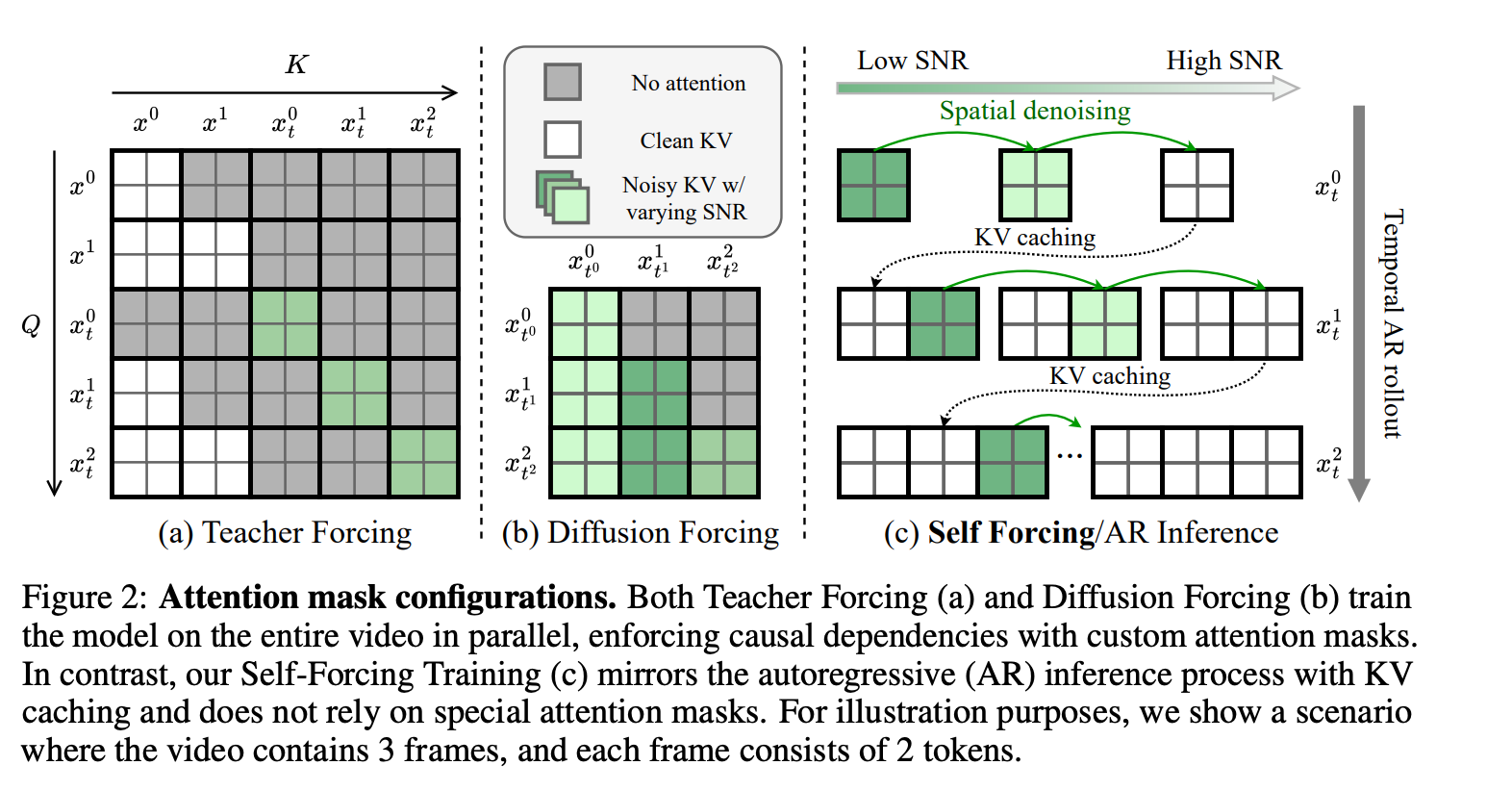 Attention 机制对比:改进版 TF、DF 与 SF(SF 采用 Full Attention,每个 chunk 自回归展开)
Attention 机制对比:改进版 TF、DF 与 SF(SF 采用 Full Attention,每个 chunk 自回归展开)
4. Causal Forcing
论文: Causal Forcing: Autoregressive Diffusion Distillation Done Right
从理论角度指出 CausVid 直接从双向教师蒸馏到自回归学生的缺陷——违反了 PF-ODE 的帧级单射性 (frame-level injectivity) 条件,导致学生模型退化为条件期望解。
Causal Forcing 在 DMD 蒸馏阶段复刻了 Self Forcing 的自回归展开,关键改进在 ODE 初始化阶段:先将双向多步扩散模型转为多步自回归扩散模型(使用 Teacher Forcing),再进行 ODE 蒸馏,以满足单射性条件。
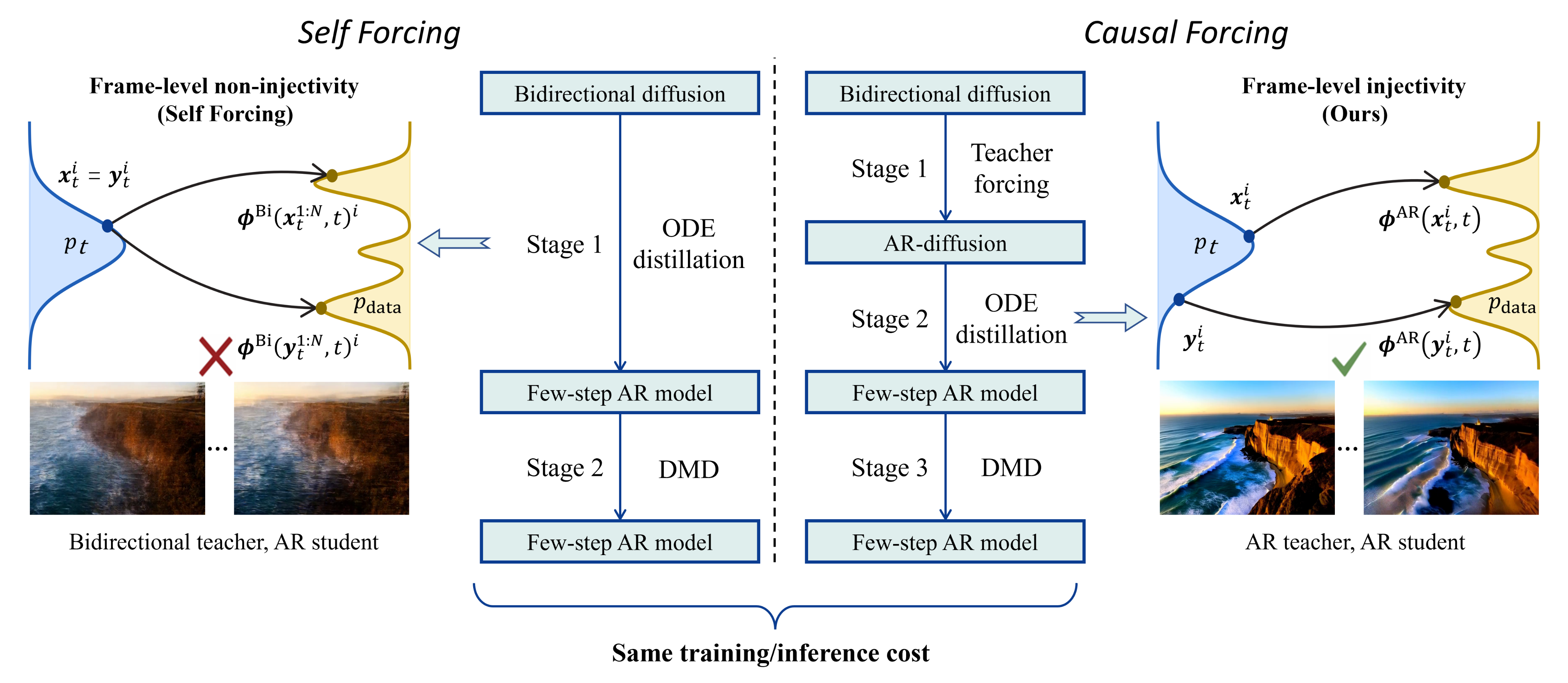 Causal Forcing 训练流程
Causal Forcing 训练流程
World Model(交互式世界模型)
以下是近期交互式世界模型的代表性工作,主要聚焦于游戏场景中的动作条件化视频生成。
一个有用的工具:WMFactory — 统一前端,支持各种交互式世界模型的部署与体验。
OASIS
代码: open-oasis
最早期的交互式世界模型之一,架构相对简单,为后续工作奠定了基础。
 OASIS 架构
OASIS 架构
GameFactory [ICCV 2025]
论文: GameFactory: Creating New Games with Generative Interactive Videos | 代码: GitHub
数据集:GF-Minecraft(3 种子 × 3 天气 × 6 时间段,共 2000 段视频,每段 2000 帧,约 130 GB)。HuggingFace 链接
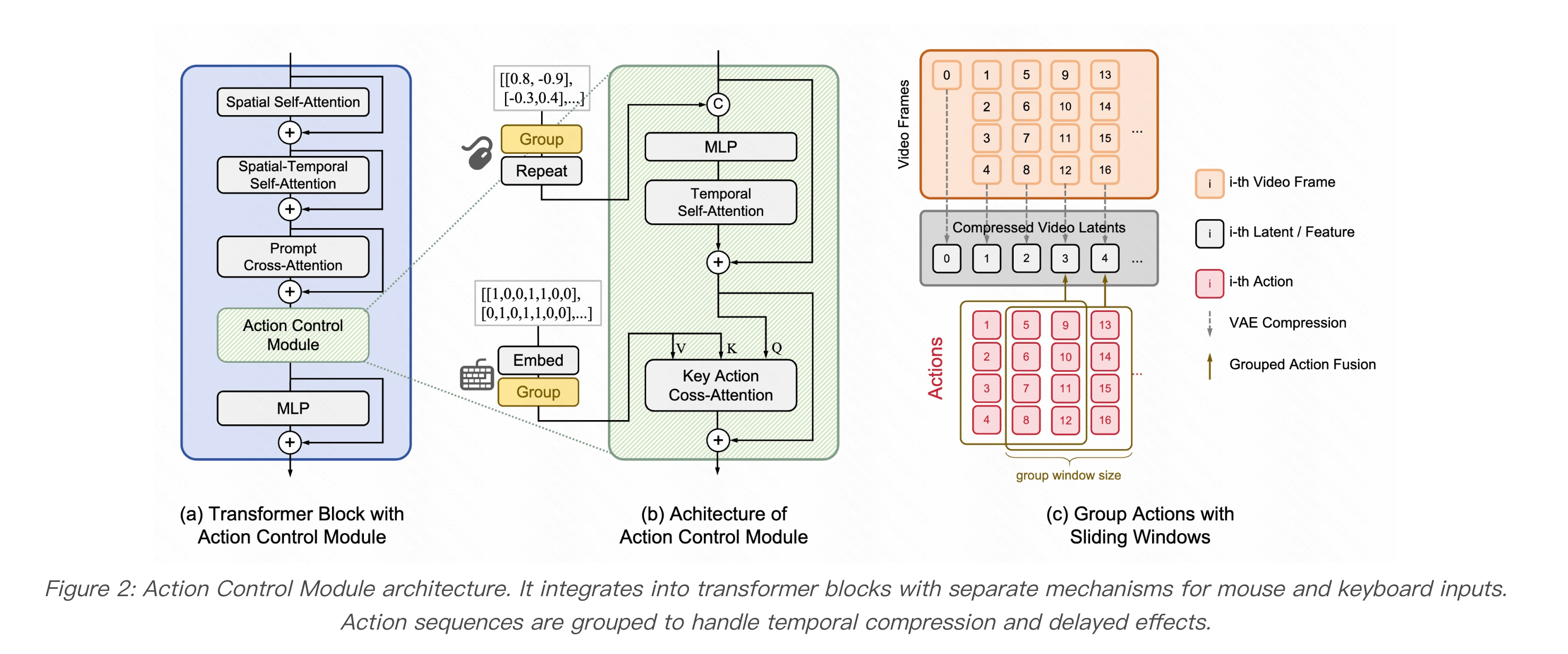 GameFactory 整体架构
GameFactory 整体架构
动作控制模块 (Action Control Module):
- 滑动窗口分组 (Sliding Window Grouping):视频模型通常在时间维度上进行压缩(如 16 帧压缩至 4 帧特征),导致特征帧数与高频动作对不齐。滑动窗口将对应时间段内的动作打包,同时模拟动作的延迟效应(如按下跳跃键后的数帧腾空)
- 键鼠分治处理:
- 鼠标(连续):与视频特征直接拼接 (Concatenation)
- 键盘(离散):通过 Cross-Attention 融合——键盘信号作为 Key/Value,视频特征作为 Query
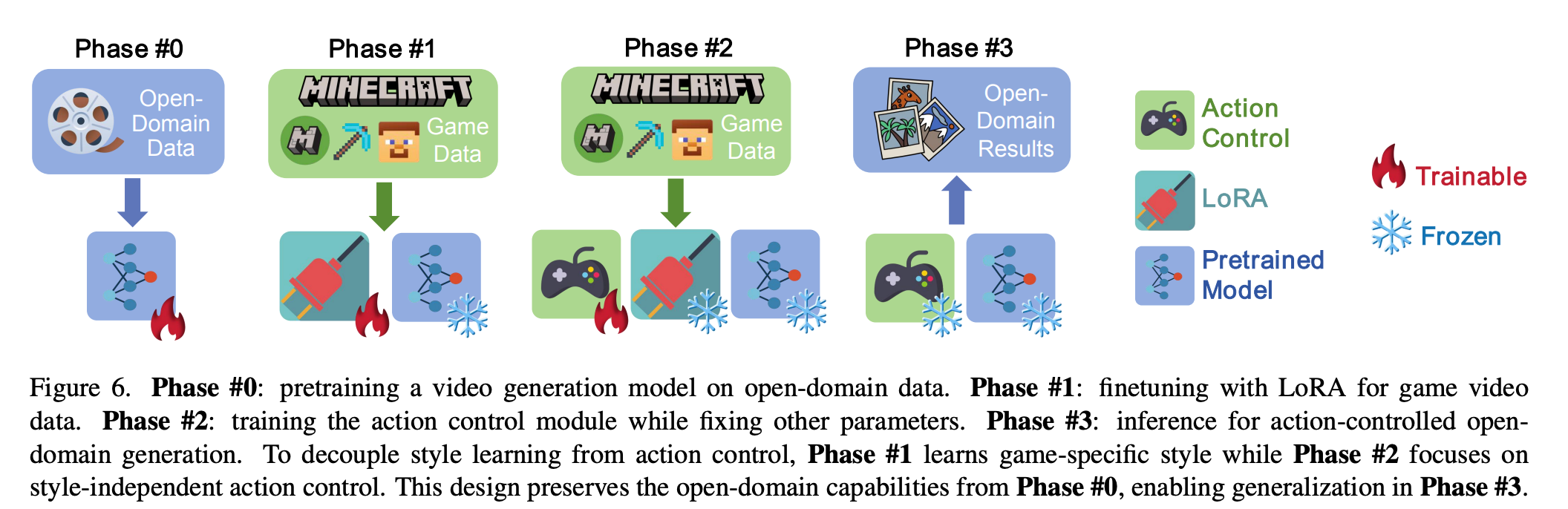 GameFactory 训练流程
GameFactory 训练流程
Phase 2 仅用少量 Minecraft 数据训练 Action Control Module。训练/推理采用 Diffusion Forcing。
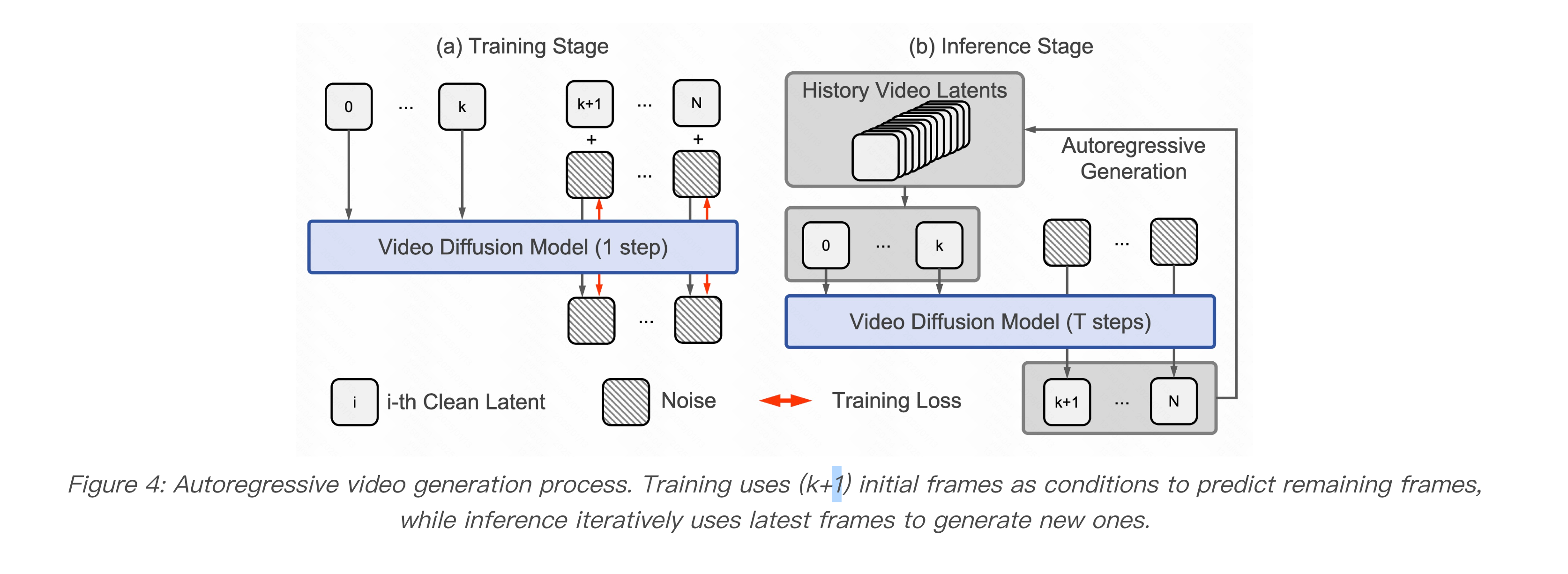 GameFactory 生成过程
GameFactory 生成过程
Matrix-Game 2.0
论文: Matrix-Game 2.0: An Open-Source Real-Time and Streaming Interactive World Model
基于 Skyreels-V2 作为 base model,完整复刻 Self Forcing 训练范式——先 ODE 初始化学生模型,再通过 DMD 完成蒸馏。
 Matrix-Game 2.0 整体架构
Matrix-Game 2.0 整体架构
动作注入:设计独立的 Action Module,连续的鼠标移动直接 Concat,离散的键盘动作通过 Cross-Attention 注入(同 Solaris、GameFactory)。
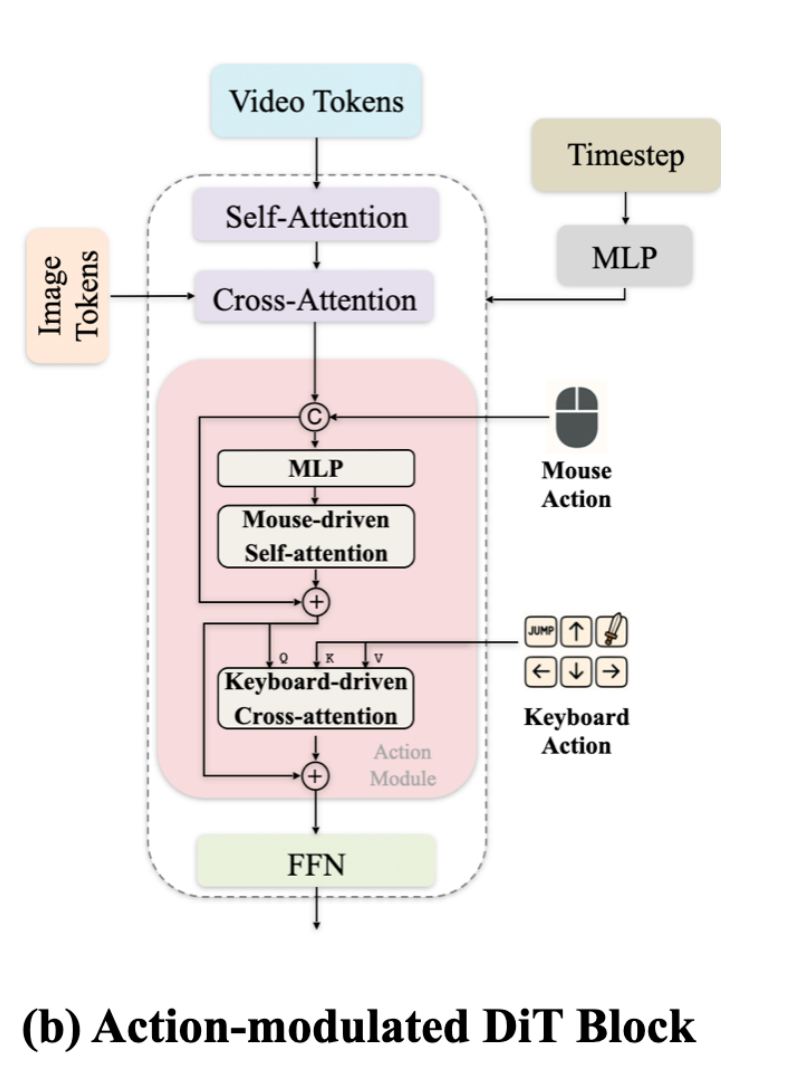 Matrix-Game 2.0 Action 注入
Matrix-Game 2.0 Action 注入
Solaris
论文: Solaris: Building a Multiplayer Video World Model in Minecraft (by Saining Xie 等)
在 Matrix-Game 2.0 基础上引入多玩家支持并改进训练流程,动作注入方案不变。
 Solaris 整体架构
Solaris 整体架构
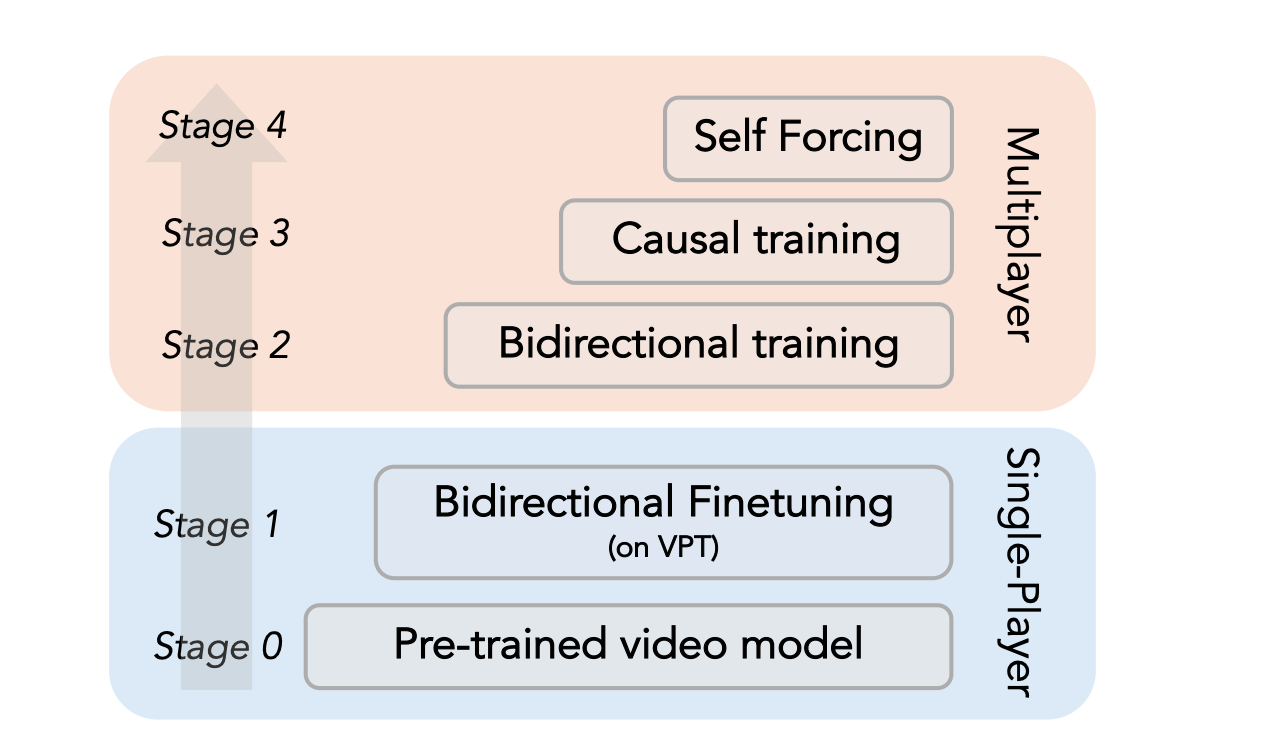
四阶段训练流程:
阶段 1:在 VPT(OpenAI 的 Minecraft 数据集)上微调双向模型(120K steps,33 帧)
阶段 2:改进 DiT 架构以支持多玩家
- 每个 player 的 token 使用独立的 3D RoPE
- 在 Multiplayer Shared Self-Attention Layer 开头,通过 Learned Player ID Embeddings 注入玩家信息
- 在数据集上进行 full-sequence 双向训练(120K steps)——此模型将作为 Self Forcing 中的 teacher
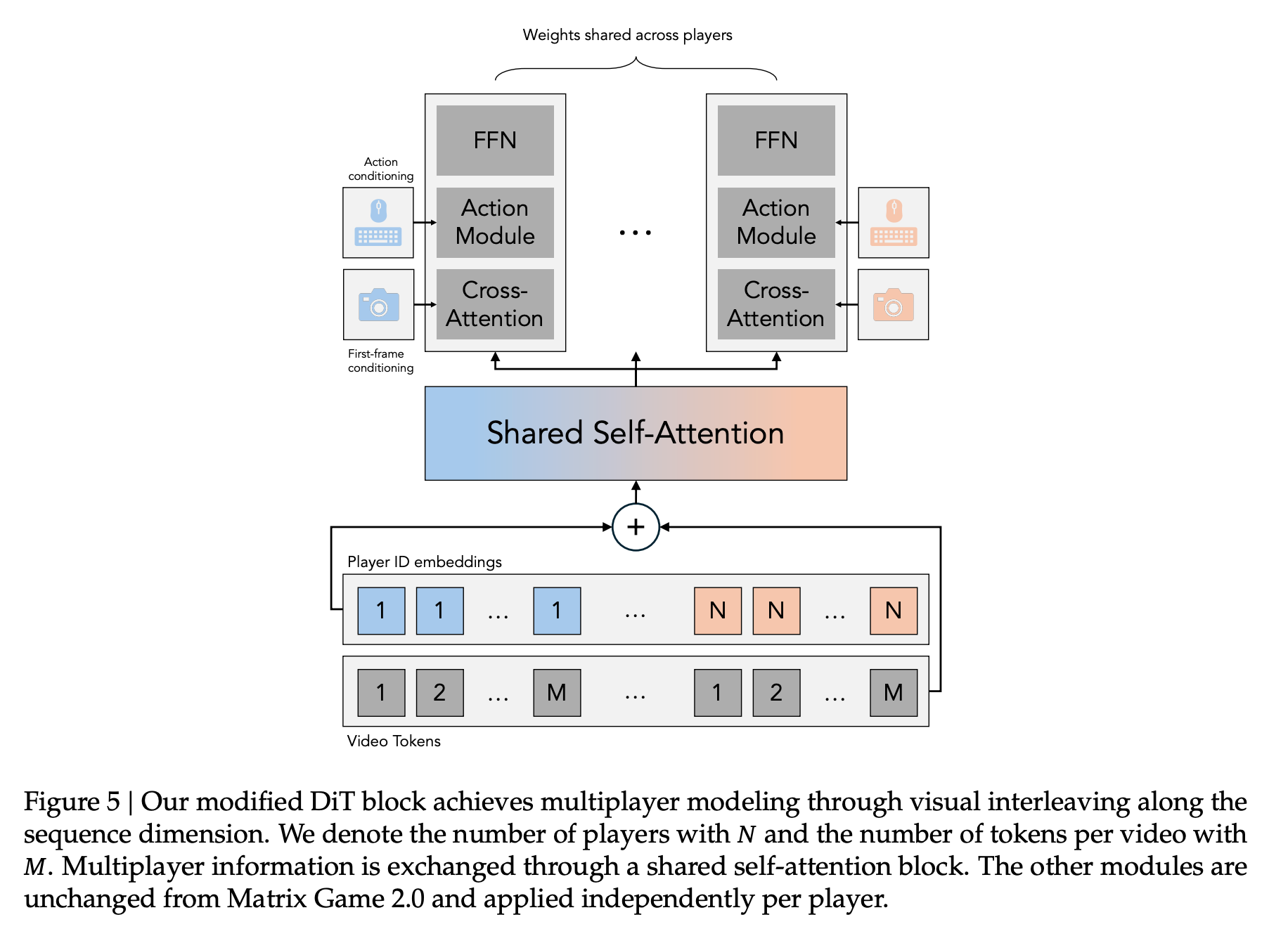 Solaris 多玩家注意力机制
Solaris 多玩家注意力机制
阶段 3:Causal Training
- 用双向训练的 60K steps checkpoint 初始化 causal model
- 采用 6 latent frames 的滑动窗口 attention mask(同时也是推理时 KV cache 的最大窗口)
- 使用 Diffusion Forcing 训练,产出模型作为 Self Forcing 的 Generator(学生模型)
- 关键发现:不需要复杂的 ODE 回归初始化,直接将 Diffusion Forcing 产出的模型用作 Self Forcing 的 Generator 即可(与 LingbotWorld 的结论一致)
阶段 4:Self Forcing
- 扩展 Teacher 的 context 长度,使 Student 从更强大的 Teacher 中获益
- 提出 Checkpointed Self Forcing 解决滑动窗口设置下显存不足的问题:先禁用梯度生成初始视频并缓存中间加噪帧,再在启用反向传播的额外 step 中重新计算最终视频,从而解耦自回归 rollout 与反向传播
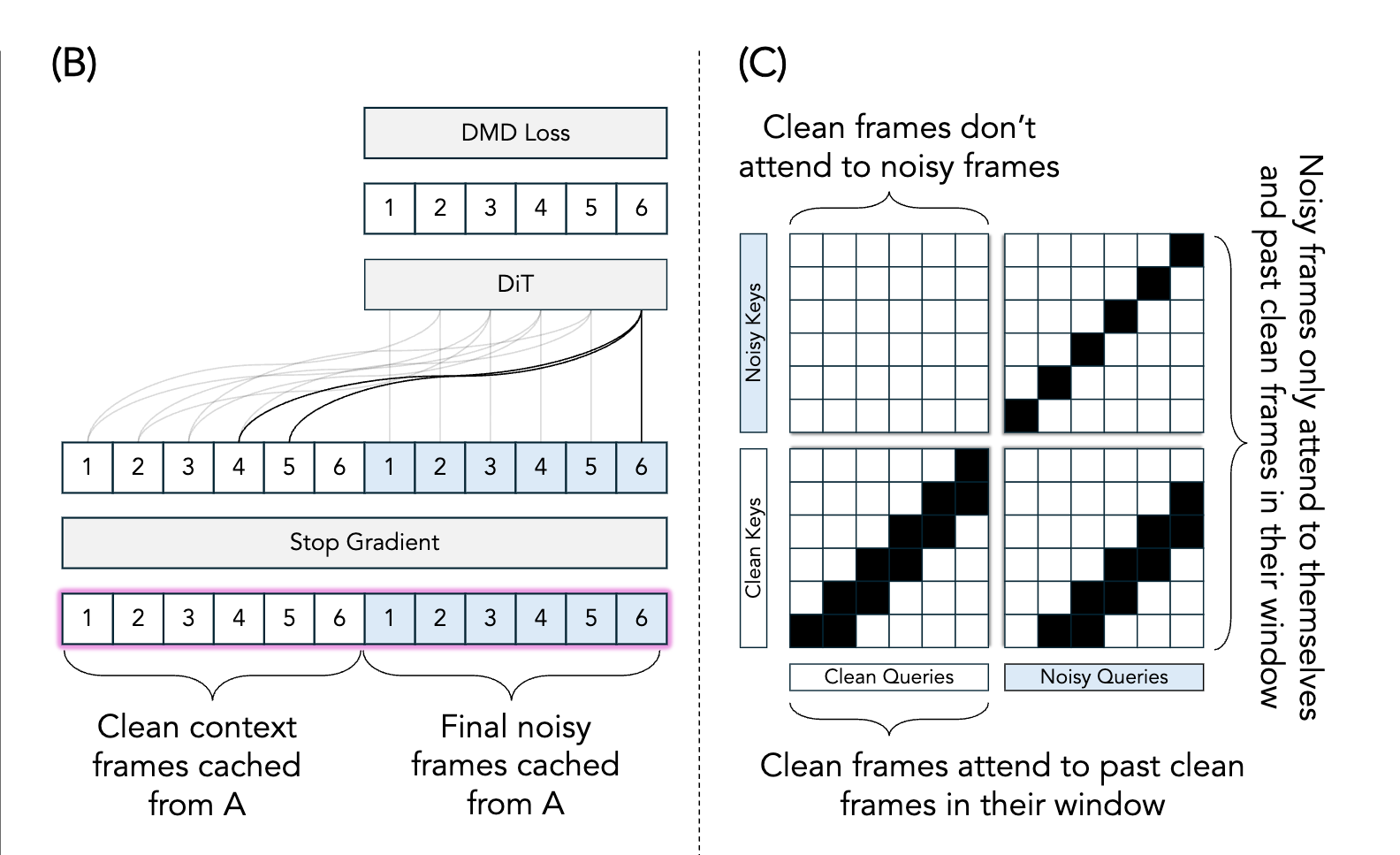 Solaris Self Forcing 流程
Solaris Self Forcing 流程
Attention 机制解读:将 6 个 Clean Frames 和 6 个 Noisy Frames concat 后:
- Clean Queries:只看自身以及窗口内前面的 clean frames,不看 noisy frames
- Noisy Frames:只看自身加噪版本以及窗口内前面的干净帧
- 通过一次 forward pass 复现了逐帧自回归展开的效果,同时梯度可以完整流经整个注意力的 QKV
HYWorldPlay
技术报告: HYWorld 1.5 Tech Report
基于 Wan-5B / HY-8B,分四个阶段训练:
 HYWorldPlay 四阶段训练流程
HYWorldPlay 四阶段训练流程
- 使用 Diffusion Forcing 训出 Chunk-wise AR Diffusion Model(类似 Solaris)
- 动作注入:
- 离散的键盘和鼠标:用零初始化 MLP 投影 Action Embeddings,注入到 timestep embedding(AdaLN 调制器)
- 连续的相机位姿:通过 PRoPE 注入到 Self-Attention Blocks
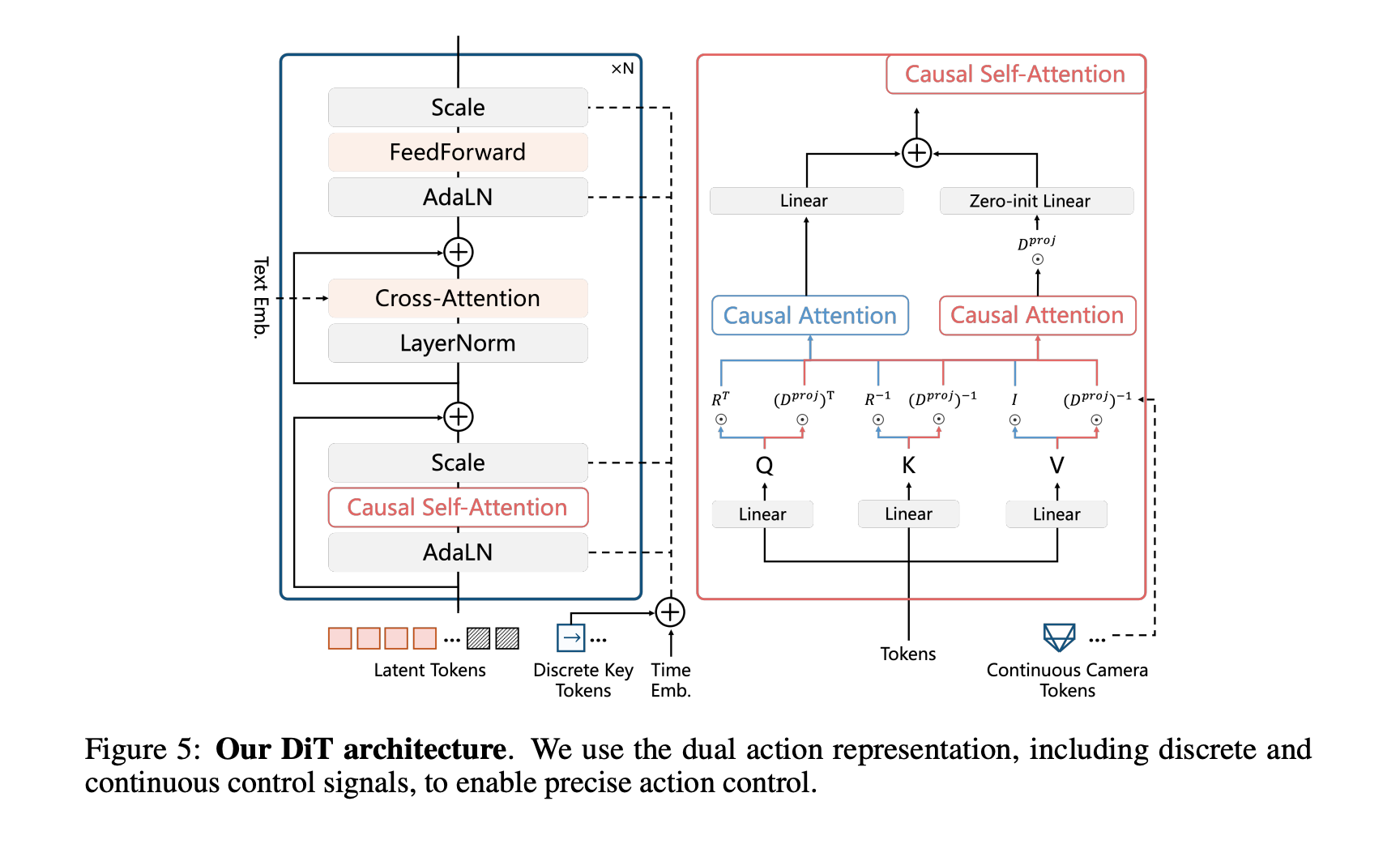 HYWorldPlay Action 注入方式
HYWorldPlay Action 注入方式
- 重新设计的 Context Memory:
- Short-term temporal clues:保留最近 L 个 chunk,维持短时动作平滑
- Long-range spatial references:Spatial Memory 从非相邻历史帧中采集,由几何相关性评分指导(结合 FOV 重叠和相机距离)
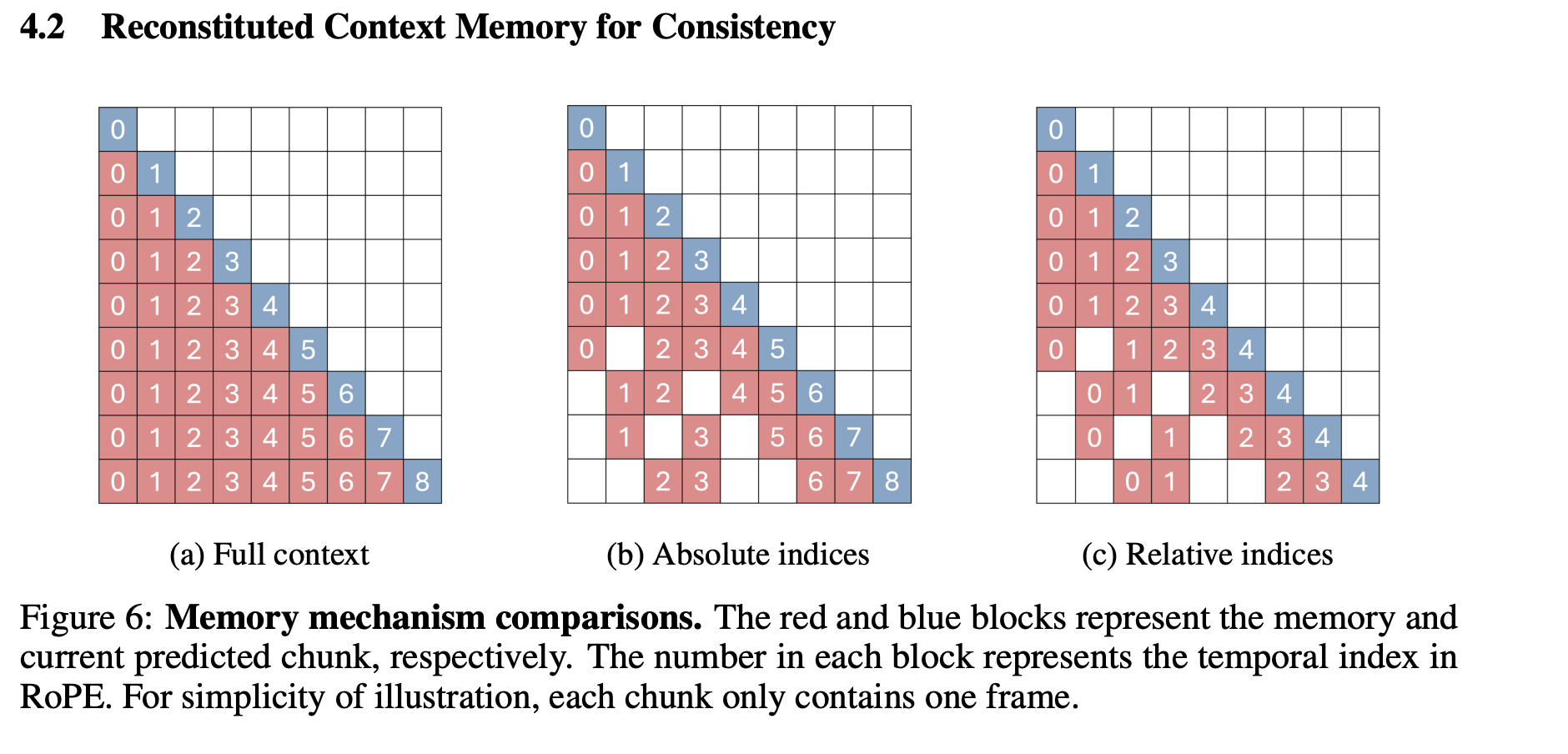 HYWorldPlay Context Memory
HYWorldPlay Context Memory
- 后训练:
- Stage I:使用 WorldCompass 进行 RL 训练(已开源)
- Stage II:提出 Context Forcing 蒸馏方法(未开源,类似 Self Forcing)——将学生 Self-Rollout 生成 4 个 chunks 所用的 Memory 传给教师,使教师在相同 memory 条件下进行 Distribution Matching
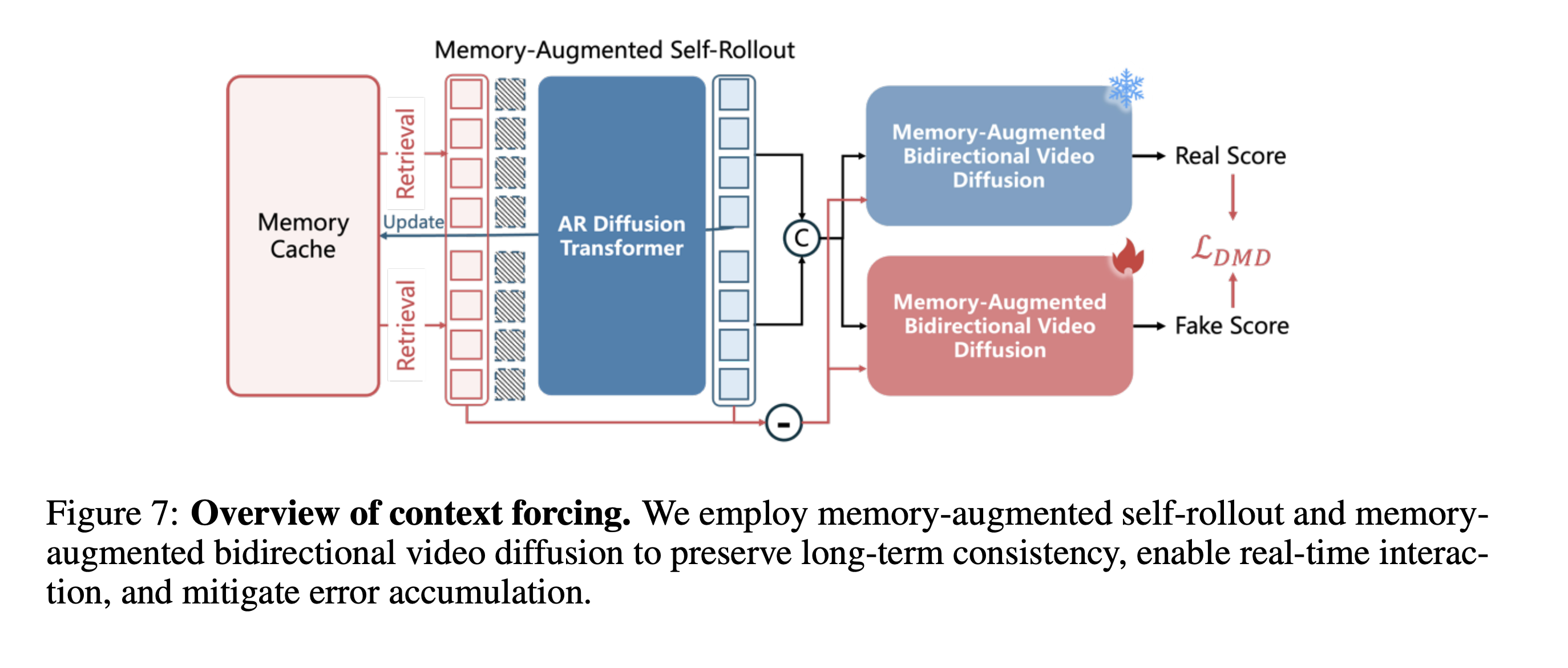 HYWorldPlay 后训练蒸馏
HYWorldPlay 后训练蒸馏
LingbotWorld
论文: LingbotWorld
基于 Wan 2.1 14B I2V Model,三阶段训练:
- General 视频先验学习
- 注入 Action,训练保持 long-term 一致性(双向阶段)
- Causal Attention + Few-Step 蒸馏
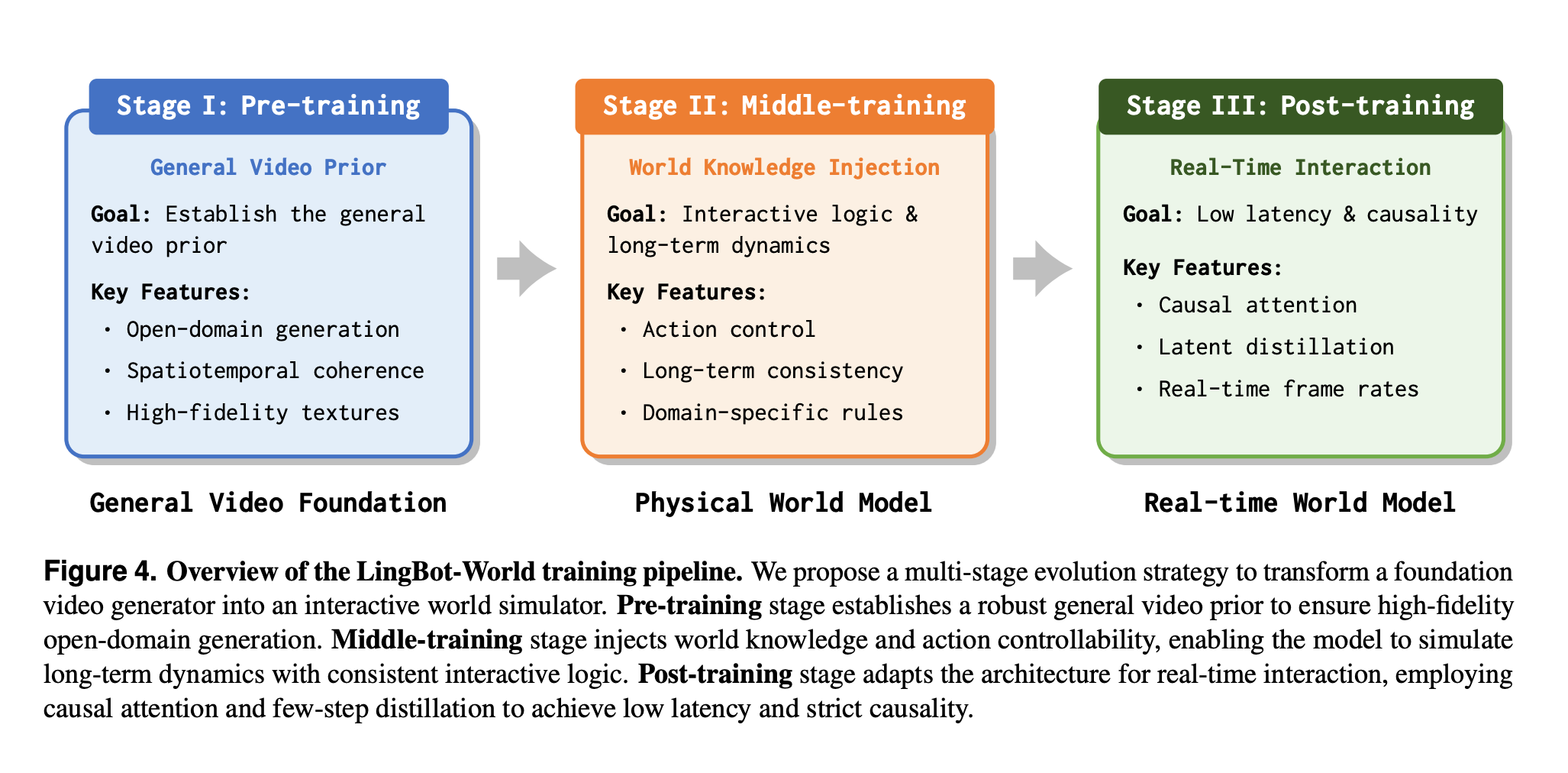 LingbotWorld 训练流程
LingbotWorld 训练流程
动作注入:将连续和离散信号统一处理——连续信号用 Plucker Embeddings,离散信号用 Multi-hop Vectors,两者在 channel 维度 Concat 后注入 AdaLN 调制器(与 HYWorldPlay 的离散注入类似)。训练时仅微调新加入的 Action Embeddings Projection 层和 AdaLN 参数,backbone 冻结。
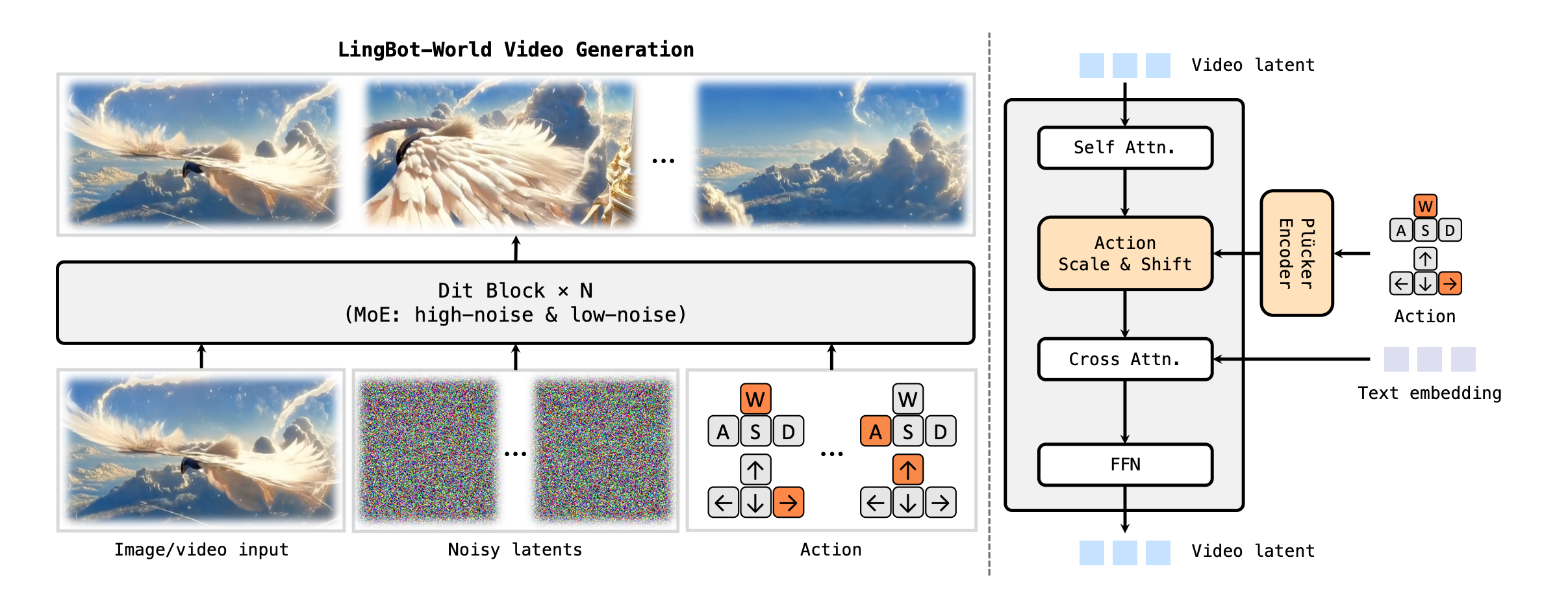 LingbotWorld 动作注入
LingbotWorld 动作注入
训练范式:先用 Diffusion Forcing 将双向模型转为 AR 模型,再用 Self Forcing 蒸馏为少步模型(直接以 Diffusion Forcing 产出作为 Teacher,无需 ODE 初始化——与 Solaris 的结论一致)。
Matrix-Game 3.0
代码: Matrix-Game 3.0
基于 Wan 2.1 5B,开创性地放弃了 Self Forcing + Causal Attention Mask 的范式:
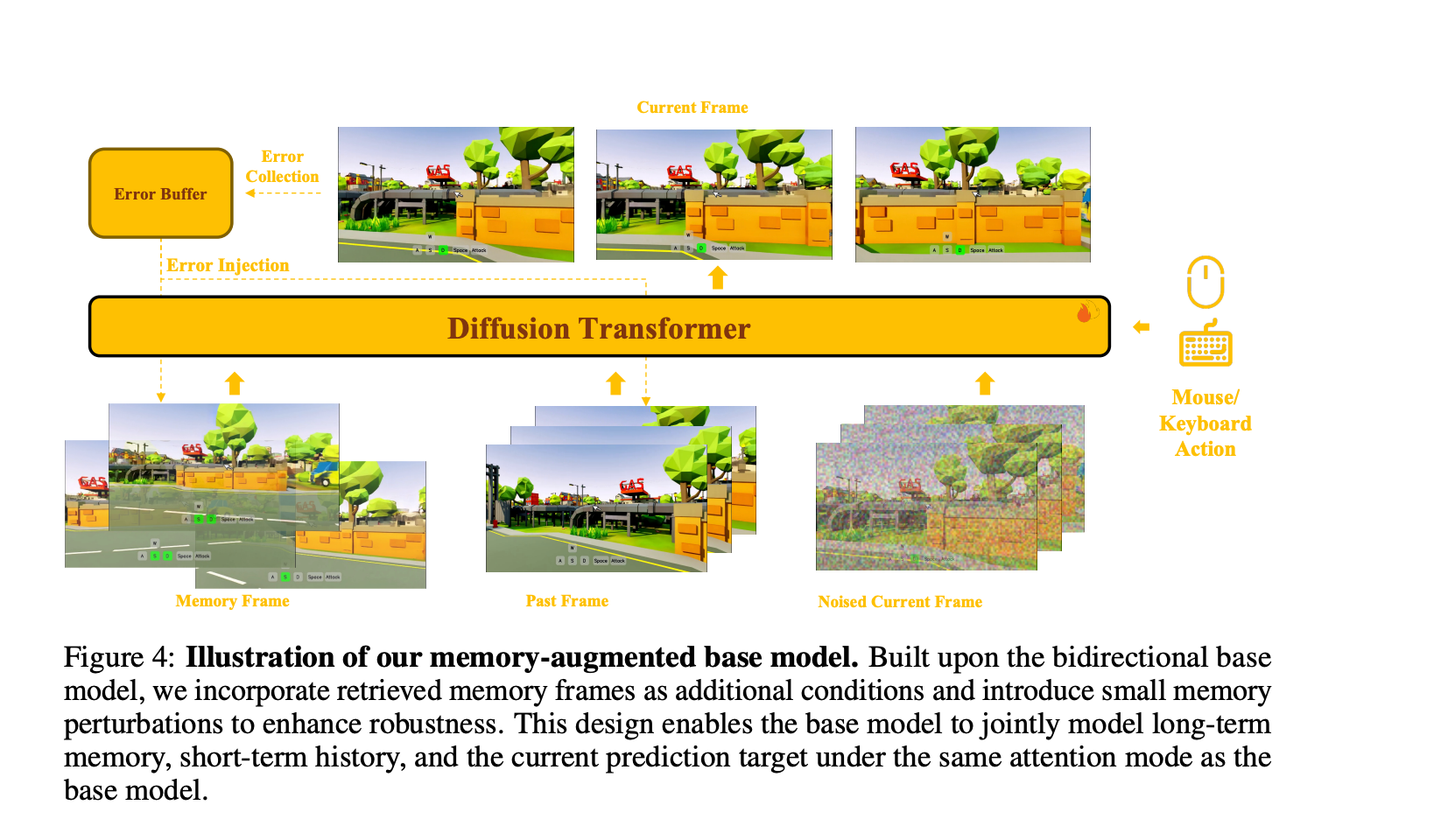 Matrix-Game 3.0 架构
Matrix-Game 3.0 架构
- 每次只生成一个 segment(56 帧),segment 内部使用 full attention,不对之前帧做注意力,仅通过 overlap 重叠 + memory 进行条件化
- 56 帧中 16 帧为 overlap,每次前进 40 帧
- 从 40 帧中取 5 个关键帧,通过 FOV 重叠 / 相机位姿检索 5 个相似的 Memory 帧,获取对应的 5 个 latent frames
- 最终将 5 个 memory latent frames 与 14 个 segment 内 latent frames 合并,进行双向 full attention diffusion
 Matrix-Game 3.0 Memory + Overlap 机制
Matrix-Game 3.0 Memory + Overlap 机制
此外还提出了一种 Training-Inference Aligned 的少步蒸馏方法。
总结
动作注入方式
| 方案 | 代表工作 |
|---|---|
| Action Module:连续信号 Concat + 离散信号 Cross-Attention | Matrix-Game 2.0/3.0, Solaris, GameFactory |
| Action Embeddings 注入 AdaLN 调制器 | HYWorldPlay, LingbotWorld |
训练范式
核心目标:将双向模型训成 AR 模型 + 将多步模型蒸馏为少步模型。
| 训练方式 | 代表工作 |
|---|---|
| Diffusion Forcing | GameFactory |
| Self Forcing | Matrix-Game 2.0 |
| Diffusion Forcing → Self Forcing (其中Stage 2) | Solaris, LingbotWorld |
| 非 Causal Attention + Forcing 范式 (Segment-based) | Matrix-Game 3.0 |